這篇文章介紹下mybatis的一級緩存的生命周期
一級緩存的產生
一級緩存的產生,並不是看mappper的xml文件的select方法,看下面的例子
mapper.xml
<select id="getById" resultType="entity.TempEntity">
select * from temp where id = #{id}
</select>
test
@Test
public void testSelectAsUpdate() throws IOException {
InputStream inputStream = Resources.getResourceAsStream("mybatis.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
sqlSession.update("dao.Temp03Dao.getById", 1);
sqlSession.update("dao.Temp03Dao.getById", 1);
}
執行結果
2020-06-26 17:33:27,899 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:33:27,922 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:33:27,923 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:33:27,923 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
我們可以看到執行了2次查詢。說明並沒有產生緩存。說明和sqlsession調用的方法是有關係的
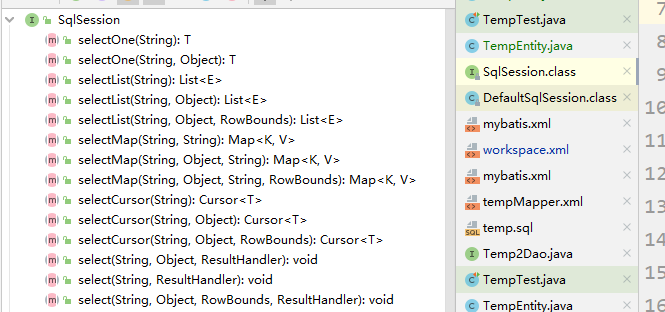
只有調用上圖中的方法才會產生一級緩存
一級緩存的銷毀
1.關閉session
這個是根據debug看到的一級緩存的最終結構。下面是整個依賴的類圖
test
@Test
public void test() throws IOException, NoSuchFieldException, IllegalAccessException {
InputStream inputStream = Resources.getResourceAsStream("mybatis.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
TempEntity tempEntity1 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity1);
Field executorField = sqlSession.getClass().getDeclaredField("executor");
executorField.setAccessible(true);
CachingExecutor cachingExecutor = (CachingExecutor) executorField.get(sqlSession);
Field declaredField = cachingExecutor.getClass().getDeclaredField("delegate");
declaredField.setAccessible(true);
SimpleExecutor simpleExecutor = (SimpleExecutor) declaredField.get(cachingExecutor);
Field localCacheField = simpleExecutor.getClass().getSuperclass().getDeclaredField("localCache");
localCacheField.setAccessible(true);
PerpetualCache perpetualCache = (PerpetualCache) localCacheField.get(simpleExecutor);
Field cacheField = perpetualCache.getClass().getDeclaredField("cache");
cacheField.setAccessible(true);
Map<Object,Object> map= (Map<Object, Object>) cacheField.get(perpetualCache);
logger.info("緩存關閉前");
for (Map.Entry<Object,Object> objectObjectEntry:map.entrySet()){
logger.info(objectObjectEntry.getKey() + "===" + objectObjectEntry.getValue());
}
sqlSession.close();
logger.info("緩存關閉后");
for (Map.Entry<Object,Object> objectObjectEntry:map.entrySet()){
logger.info(objectObjectEntry.getKey() + "=" + objectObjectEntry.getValue());
}
}
運行結果
2020-06-26 17:38:52,777 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:38:52,801 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:38:52,824 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:38:52,824 INFO [TempTest] - TempEntity{id=1, value1='11111', value2='aaaaa'}
2020-06-26 17:38:52,825 INFO [TempTest] - 緩存關閉前
2020-06-26 17:38:52,826 INFO [TempTest] - -1654591322:461730790:dao.Temp03Dao.getById:0:2147483647:select * from temp where id = ?:1:dev===[TempEntity{id=1, value1='11111', value2='aaaaa'}]
2020-06-26 17:38:52,827 INFO [TempTest] - 緩存關閉后
可以看到session關閉后,緩存就不存在了
2.Commit提交
test
@Test
public void testCommit() throws IOException {
InputStream inputStream = Resources.getResourceAsStream("mybatis.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
TempEntity tempEntity1 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity1);
sqlSession.commit();
TempEntity tempEntity2 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity2);
logger.info(tempEntity1 == tempEntity2);
}
運行結果
2020-06-26 17:40:40,821 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:40:40,846 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:40:40,862 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:40:40,862 INFO [TempTest] - TempEntity{id=1, value1='11111', value2='aaaaa'}
2020-06-26 17:40:40,863 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:40:40,863 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:40:40,864 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:40:40,864 INFO [TempTest] - TempEntity{id=1, value1='11111', value2='aaaaa'}
2020-06-26 17:40:40,864 INFO [TempTest] - false
說明sqlSession.commit時會清空緩存
3.Rollback
test
@Test
public void testRollback() throws IOException {
InputStream inputStream = Resources.getResourceAsStream("mybatis.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
TempEntity tempEntity1 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity1);
sqlSession.rollback();
TempEntity tempEntity2 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity2);
logger.info(tempEntity1 == tempEntity2);
}
執行結果
2020-06-26 17:42:23,793 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:42:23,833 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:42:23,843 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:42:23,843 INFO [TempTest] - TempEntity{id=1, value1='11111', value2='aaaaa'}
2020-06-26 17:42:23,844 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:42:23,844 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:42:23,845 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:42:23,845 INFO [TempTest] - TempEntity{id=1, value1='11111', value2='aaaaa'}
2020-06-26 17:42:23,845 INFO [TempTest] - false
sqlSession.rollback()也會清空緩存
4.update更新
這裡是在第一次查詢后,緊接着進行update操作。這裏與表無關。就是操作其它表,也會清空緩存。
test
@Test
public void testForUpdate() throws IOException {
InputStream inputStream = Resources.getResourceAsStream("mybatis.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
TempEntity tempEntity1 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity1);
sqlSession.update("dao.Temp03Dao.updateById", 1);
TempEntity tempEntity2 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity2);
logger.info(tempEntity1 == tempEntity2);
}
運行結果
2020-06-26 17:45:43,997 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:45:44,034 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:45:44,048 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:45:44,049 INFO [TempTest] - TempEntity{id=1, value1='11111', value2='aaaaa'}
2020-06-26 17:45:44,049 DEBUG [dao.Temp03Dao.updateById] - ==> Preparing: update temp set value1 = 'ffffff' where id = ?
2020-06-26 17:45:44,049 DEBUG [dao.Temp03Dao.updateById] - ==> Parameters: 1(Integer)
2020-06-26 17:45:44,050 DEBUG [dao.Temp03Dao.updateById] - <== Updates: 1
2020-06-26 17:45:44,051 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:45:44,051 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:45:44,052 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:45:44,053 INFO [TempTest] - TempEntity{id=1, value1='ffffff', value2='aaaaa'}
2020-06-26 17:45:44,053 INFO [TempTest] - false
這裏還是在一個session會話中。記得之前有人給我說只要在一個session會話中,執行update不會清空緩存。這裏的代碼就證明了
5.clearCache 主動清除
test
@Test
public void testClearCatch() throws IOException {
InputStream inputStream = Resources.getResourceAsStream("mybatis.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = build.openSession();
TempEntity tempEntity1 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity1);
sqlSession.clearCache();
TempEntity tempEntity2 = sqlSession.selectOne("dao.Temp03Dao.getById", 1);
logger.info(tempEntity2);
logger.info(tempEntity1 == tempEntity2);
}
運行結果
2020-06-26 17:48:42,085 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:48:42,110 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:48:42,124 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:48:42,124 INFO [TempTest] - TempEntity{id=1, value1='11111', value2='aaaaa'}
2020-06-26 17:48:42,125 DEBUG [dao.Temp03Dao.getById] - ==> Preparing: select * from temp where id = ?
2020-06-26 17:48:42,125 DEBUG [dao.Temp03Dao.getById] - ==> Parameters: 1(Integer)
2020-06-26 17:48:42,126 DEBUG [dao.Temp03Dao.getById] - <== Total: 1
2020-06-26 17:48:42,126 INFO [TempTest] - TempEntity{id=1, value1='11111', value2='aaaaa'}
2020-06-26 17:48:42,126 INFO [TempTest] - false
一級緩存 臟讀問題
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!