redis簡介
redis是一個key-value存儲系統。和Memcached類似,它支持存儲的value類型相對更多,包括string(字符串)、list(鏈表)、set(集合)、zset(sorted set –有序集合)和hash(哈希類型)。與memcached一樣,為了保證效率,數據都是緩存在內存中。區別的是redis會周期性的把更新的數據寫入磁盤或者把修改操作寫入追加的記錄文件,並且在此基礎上實現master-slave(主從)同步。
Redis詳細請看我專門寫的redis
https://www.cnblogs.com/you-men/tag/Redis/
如何保持session會話
目前,為了使web能適應大規模的訪問,需要實現應用的集群部署。集群最有效的方案就是負載均衡,而實現負載均衡用戶每一個請求都有可能被分配到不固定的服務器上,這樣我們首先要解決session的統一來保證無論用戶的請求被轉發到哪個服務器上都能保證用戶的正常使用,即需要實現session的共享機制。
在集群系統下實現session統一的有如下幾種方案:
1、請求精確定位:sessionsticky,例如基於訪問ip的hash策略,即當前用戶的請求都集中定位到一台服務器中,這樣單台服務器保存了用戶的session登錄信息,如果宕機,則等同於單點部署,會丟失,會話不複製。
2、session複製共享:sessionreplication,如tomcat自帶session共享,主要是指集群環境下,多台應用服務器之間同步session,使session保持一致,對外透明。 如果其中一台服務器發生故障,根據負載均衡的原理,調度器會遍歷尋找可用節點,分發請求,由於session已同步,故能保證用戶的session信息不會丟失,會話複製,。
此方案的不足之處:
必須在同一種中間件之間完成(如:tomcat-tomcat之間).
session複製帶來的性能損失會快速增加.特別是當session中保存了較大的對象,而且對象變化較快時, 性能下降更加顯著,會消耗系統性能。這種特性使得web應用的水平擴展受到了限制。
Session內容通過廣播同步給成員,會造成網絡流量瓶頸,即便是內網瓶頸。在大併發下錶現並不好
3、基於cache DB緩存的session共享
基於memcache/redis緩存的 session 共享
即使用cacheDB存取session信息,應用服務器接受新請求將session信息保存在cache DB中,當應用服務器發生故障時,調度器會遍歷尋找可用節點,分發請求,當應用服務器發現session不在本機內存時,則去cache DB中查找,如果找到則複製到本機,這樣實現session共享和高可用。
nginx+tomcat+redis實現負載均衡、session共享
環境
| 主機 | 操作系統 | IP地址 | 硬件/網絡 |
|---|---|---|---|
| Nginx | CentOS7.3 | 39.108.140.0 | 1C2G / 公有雲 |
| Tomcat-1 | CentOS7.3 | 121.36.43.2 | 1C2G / 公有雲 |
| Tomcat-2 | CentOS7.3 | 49.233.69.195 | 1C2G / 公有雲 |
| Redis | CentOS7.3 | 116.196.83.113 | 1C2G / 公有雲 |
| MySQL | CentOS7.3 | 116.196.83.113 | 1C2G / 公有雲 |
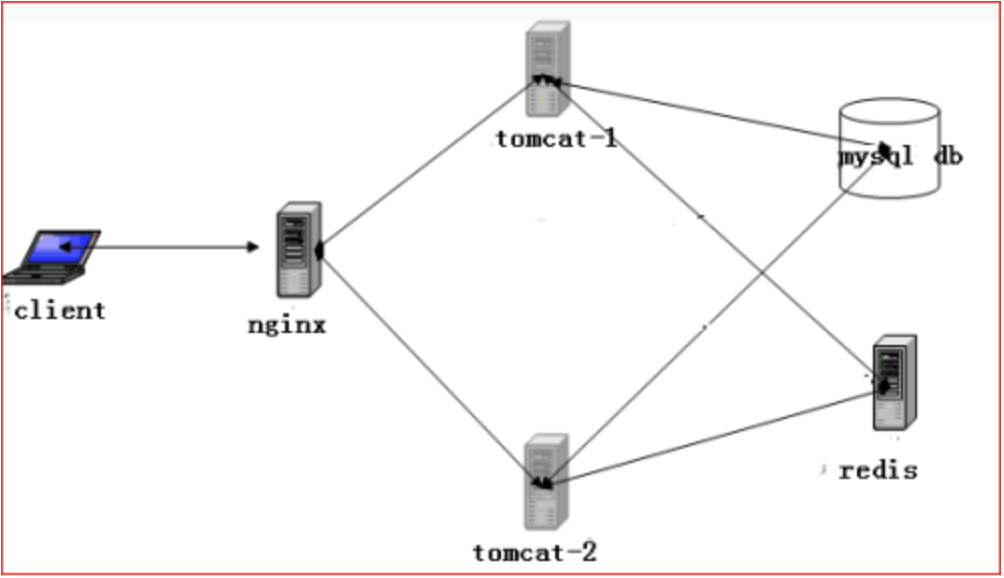
實驗拓撲
在這個圖中,nginx做為反向代理,實現靜動分離,將客戶動態請求根據權重隨機分配給兩台tomcat服務器,redis做為兩台tomcat的共享session數據服務器,mysql做為兩台tomcat的後端數據庫。
nginx安裝配置
使用Nginx作為Tomcat的負載平衡器,Tomcat的會話Session數據存儲在Redis,能夠實現零宕機的7×24效果。因為將會話存儲在Redis中,因此Nginx就不必配置成stick粘貼某個Tomcat方式,這樣才能真正實現後台多個Tomcat負載平衡。
部署nginx
#!/usr/bin/env bash
# Author: ZhouJian
# Mail: 18621048481@163.com
# Time: 2019-9-3
# Describe: CentOS 7 Install Nginx Source Code Script
version="nginx-1.14.2.tar.gz"
user="nginx"
nginx=${version%.tar*}
path=/usr/local/src/$nginx
echo $path
if ! ping -c2 www.baidu.com &>/dev/null
then
echo "網絡不通,無法安裝"
exit
fi
yum install -y gcc gcc-c++ openssl-devel pcre-devel make zlib-devel wget psmisc
if [ ! -e $version ];then
wget http://nginx.org/download/$version
fi
if ! id $user &>/dev/null
then
useradd $user -M -s /sbin/nologin
fi
if [ ! -d /var/tmp/nginx ];then
mkdir -p /var/tmp/nginx/{client,proxy,fastcgi,uwsgi,scgi}
fi
tar xf $version -C /usr/local/src
cd $path
./configure \
--prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--with-http_ssl_module \
--with-http_flv_module \
--with-http_stub_status_module \
--with-http_sub_module \
--with-http_gzip_static_module \
--with-http_auth_request_module \
--with-http_random_index_module \
--with-http_realip_module \
--http-client-body-temp-path=/var/tmp/nginx/client \
--http-proxy-temp-path=/var/tmp/nginx/proxy \
--http-fastcgi-temp-path=/var/tmp/nginx/fastcgi \
--http-uwsgi-temp-path=/var/tmp/nginx/uwsgi \
--http-scgi-temp-path=/var/tmp/nginx/scgi \
--with-pcre \
--with-file-aio \
--with-http_secure_link_module && make && make install
if [ $? -ne 0 ];then
echo "nginx未安裝成功"
exit
fi
killall nginx
/usr/local/nginx/sbin/nginx
#echo "/usr/local/nginx/sbin/nginx" >> /etc/rc.local
#chmod +x /etc/rc.local
#systemctl start rc-local
#systemctl enable rc-local
ss -antp |grep nginx
配置nginx反向代理:反向代理+負載均衡+健康探測,nginx.conf文件內容:
vim /usr/local/nginx/conf/nginx.conf
worker_processes 4;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
#blog lb by oldboy at 201303
upstream backend_tomcat {
#ip_hash;
server 192.168.6.241:8080 weight=1 max_fails=2 fail_timeout=10s;
server 192.168.6.242:8080 weight=1 max_fails=2 fail_timeout=10s;
#server 192.168.6.243:8080 weight=1 max_fails=2 fail_timeout=10s;
}
server {
listen 80;
server_name www.98yz.cn;
charset utf-8;
location / {
root html;
index index.jsp index.html index.htm;
}
location ~* \.(jsp|do)$ {
proxy_pass http://backend_tomcat;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
}
}
}
安裝部署tomcat應用程序服務器
在tomcat-1和tomcat-2節點上安裝JDK
在安裝tomcat之前必須先安裝JDK,JDK的全稱是java development kit,是sun公司免費提供的java語言的軟件開發工具包,其中包含java虛擬機(JVM),編寫好的java源程序經過編譯可形成java字節碼,只要安裝了JDK,就可以利用JVM解釋這些字節碼文件,從而保證了java的跨平台性。
安裝JDK,Tomcat 程序
tar xvf jdk-8u151-linux-x64.tar.gz -C /usr/local/
wget https://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.55/bin/apache-tomcat-8.5.55.tar.gz
tar xf apache-tomcat-8.5.55.tar.gz -C /usr/local/
cd /usr/local/
mv apache-tomcat-8.5.55/ tomcat
mv jdk1.8.0_151/ jdk
按照相同方法在tomcat-2也安裝
vim conf/server.xml
// 設置默認虛擬主機,並增加jvmRoute
<Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat-1">
// 修改默認虛擬主機,並將網站文件路徑指向/web/webapp1,在host段增加context段
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Context docBase="/web/webapp1" path="" reloadable="true"/>
</Host>
// 增加文檔目錄與測試文件
mkdir -p /web/webapp1
cd /web/webapp1
cat index.jsp
<%@page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<html>
<head>
<title>tomcat-1</title>
</head>
<body>
<h1><font color="red">Session serviced by tomcat</font></h1>
<table aligh="center" border="1">
<tr>
<td>Session ID</td>
<td><%=session.getId() %></td>
<% session.setAttribute("abc","abc");%>
</tr>
<tr>
<td>Created on</td>
<td><%= session.getCreationTime() %></td>
</tr>
</table>
tomcat-1
</body>
<html>
// 接下來我們將tomcat和nginx都啟動起來,可以發現用戶訪問index.jsp會一會跳轉tomcat1,一會tomcat2,session還不一致
Tomcat-2節點與tomcat-1節點配置基本類似,只是jvmRoute不同,另外為了區分由哪個節點提供訪問,測試頁標題也不同(生產環境兩個tomcat服務器提供的網頁內容是相同的)。其他的配置都相同。
用瀏覽器訪問nginx主機,驗證負載均衡
驗證健康檢查的方法可以關掉一台tomcat主機,用客戶端瀏覽器測試訪問。
從上面的結果能看出兩次訪問,nginx把訪問請求分別分發給了後端的tomcat-1和tomcat-2,客戶端的訪問請求實現了負載均衡,但sessionid並一樣。所以,到這裏我們準備工作就全部完成了,下面我們來配置tomcat通過redis實現會話保持。
安裝redis
yum -y install gcc
wget http://download.redis.io/releases/redis-4.0.14.tar.gz
tar xvf redis-4.0.14.tar.gz -C /opt/
cd /opt/redis-4.0.14
編譯安裝
# Redis的編譯,只將命令文件編譯,將會在當前目錄生成bin目錄
make && make install PREFIX=/usr/local/redis
cd ..
mv redis-4.0.14/* /usr/local/redis/
# 創建環境變量
echo 'PATH=$PATH:/usr/local/redis/src/' >> /etc/profile
source /etc/profile
# 此時在任何目錄位置都可以是用redis-server等相關命令
[root@redis1 ~]# redis-
redis-benchmark redis-check-rdb redis-sentinel redis-trib.rb
redis-check-aof redis-cli redis-server
配置Redis
# 設置後台啟動
# 由於Redis默認是前台啟動,不建議使用.可以修改為後台
daemonize yes
# 禁止protected-mode yes/no(保護模式,是否只允許本地訪問)
protected-mode
# 設置遠程訪問
# Redis默認只允許本機訪問,把bind修改為bind 0.0.0.0 此設置會變成允許所有遠程訪問,如果指定限制訪問,可設置對應IP。
# bind指定是redis所在服務器網卡的IP,不指定本機網卡IP,可能導致你的Redis實例無法啟動
# 如果想限制IP訪問,內網的話通過網絡接口(網卡限定),讓客戶端訪問固定網卡鏈接redis
# 如果是公網,通過iptables指定某個IP允許訪問
bind 0.0.0.0
# 配置Redis日誌記錄
# 找到logfile,默認為logfile "",改為自定義日誌格式
logfile /var/log/redis_6379.log
# 把requirepass修改為123456,修改之後重啟下服務
requirepass "123456"
# 不重啟Redis設置密碼
# 在配置文件中配置requirepass的密碼(當Redis重啟時密碼依然生效)
127.0.0.1:6379> config set requirepass test123
# 查詢密碼
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "test123"
# 密碼驗證
127.0.0.1:6379> auth test123
OK
127.0.0.1:6379> set name flying
OK
127.0.0.1:6379> get name
"flying"
# 遠程主機連接
# redis-cli -h redis_ip -p redis_port -a password
啟動測試
# 放到後台輸出,redis自帶日誌了,可以輸出到黑洞
nohup redis-server /usr/local/redis/redis.conf &> /usr/local/redis/redis.log &
# 關閉命令
redis-cli -h 127.0.0.1 -p 6379 -a 123456 shutdown
# 注意:不建議使用 kill -9,這種方式不但不會做持久化操作,還會造成緩衝區等資源不能優雅關閉。極端情況下造成 AOF 和 複製丟失數據 的情況。
# shutdown 還有一個參數,代表是否在關閉 redis 前,生成 持久化文件,命令為 redis-cli shutdown nosave|save。
# 設置開機自啟動
echo "redis-server /usr/local/redis.conf" >> /etc/rc.local
配置tomcat session redis同步
通過TomcatClusterRedisSessionManager,這種方式支持redis3.0的集群方式
下載TomcatRedisSessionManager-2.0.zip包,https://github.com/ran-jit/tomcat-cluster-redis-session-manager,放到$TOMCAT_HOMA/lib下,並解壓
cd /usr/local/tomcat/lib/
wget https://github.com/ran-jit/tomcat-cluster-redis-session-manager/releases/download/2.0.4/tomcat-cluster-redis-session-manager.zip
unzip tomcat-cluster-redis-session-manager.zip
cp tomcat-cluster-redis-session-manager/lib/* ./
cp tomcat-cluster-redis-session-manager/conf/redis-data-cache.properties ../conf/
cat ../conf/redis-data-cache.properties
#-- Redis data-cache configuration
//遠端redis數據庫的地址和端口
#- redis hosts ex: 127.0.0.1:6379, 127.0.0.2:6379, 127.0.0.2:6380, ....
redis.hosts=192.168.6.244:6379
//遠端redis數據庫的連接密碼
#- redis password (for stand-alone mode)
redis.password=pwd@123
//是否支持集群,默認的是關閉
#- set true to enable redis cluster mode
redis.cluster.enabled=false
//連接redis的那個庫
#- redis database (default 0)
#redis.database=0
//連接超時時間
#- redis connection timeout (default 2000)
#redis.timeout=2000
//在這個<Context>標籤裏面配置
vim ../conf/context.xml
<Valve className="tomcat.request.session.redis.SessionHandlerValve" />
<Manager className="tomcat.request.session.redis.SessionManager" />
配置會話到期時間在../conf/web.xml
<session-config>
<session-timeout>60</session-timeout>
</session-config>
啟動tomcat服務
[root@linux-node2 lib]# ../bin/startup.sh
Tomcat-2節點與tomcat-1節點配置相同
測試,我們每次強刷他的sessionID都是一致的,所以我們認為他的session會話保持已經完成,你們也可以選擇換個客戶端的IP地址來測試
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準