※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
台中景泰電動車行只是一個單純的理由,將來台灣的環境,出門可以自由放心的深呼吸,讓空氣回歸自然的乾淨,減少污染,留給我們下一代有好品質無空污的優質環境
在上一篇博客中,我們詳細的對Q-learning的算法流程進行了介紹。同時我們使用了\(\epsilon-貪婪法\)防止陷入局部最優。
那麼我們可以想一下,最後我們得到的結果是什麼樣的呢?因為我們考慮到了所有的(\(\epsilon-貪婪法\)導致的)情況,因此最終我們將會得到一張如下的Q-Table表。
| Q-Table | \(a_1\) | \(a_2\) |
|---|---|---|
| \(s_1\) | \(q(s_1,a_1)\) | \(q(s_1,a_2)\) |
| \(s_2\) | \(q(s_2,a_1)\) | \(q(s_2,a_2)\) |
| \(s_3\) | \(q(s_3,a_1)\) | \(q(s_3,a_2)\) |
當agent運行到某一個場景\(s\)時,會去查詢已經訓練好的Q-Table,然後從中選擇一個最大的\(q\)對應的action。
訓練內容
這一次,我們將對Flappy-bird遊戲進行訓練。這個遊戲的介紹我就不多說了,可以看一下維基百科的介紹。
遊戲就是控制一隻穿越管道,然後可以獲得分數,對於小鳥來說,他只有兩個動作,跳or不跳,而我們的目標就是使小鳥穿越管道獲得更多的分數。
前置準備
因為我們的目標是來學習“強化學習”的,所以我們不可能說自己去弄一個Flappy-bird(當然自己弄也可以),這裏我們直接使用一個已經寫好的Flappy-bird。
PyGame-Learning-Environment,是一個Python的強化學習環境,簡稱PLE,下面時他Github上面的介紹:
PyGame Learning Environment (PLE) is a learning environment, mimicking the Arcade Learning Environment interface, allowing a quick start to Reinforcement Learning in Python. The goal of PLE is allow practitioners to focus design of models and experiments instead of environment design.
PLE hopes to eventually build an expansive library of games.
然後關於FlappyBird的文檔介紹在這裏,文檔的介紹還是蠻清楚的。安裝步驟如下所示,推薦在Pipenv的環境下安裝,不過你也可以直接clone我的代碼然後然後根據reademe的步驟進行使用。
git clone https://github.com/ntasfi/PyGame-Learning-Environment.git cd PyGame-Learning-Environment/ pip install -e .
需要的庫如下:
- pygame
- numpy
- pillow
函數說明
在官方文檔有幾個的函數在這裏說下,因為等下我們需要用到。
-
getGameState():獲得遊戲當前的狀態,返回值為一個字典:- player y position.
- players velocity.
- next pipe distance to player
- next pipe top y position
- next pipe bottom y position
- next next pipe distance to player
- next next pipe top y position
- next next pipe bottom y position
部分數據表示如下:
-
reset_game():重新開始遊戲 -
act(action):在遊戲中執行一個動作,參數為動作,返回執行后的分數。 -
game_over():假如遊戲結束,則返回True,否者返回False。 -
getActionSet():獲得遊戲的動作集合。※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
網站的第一印象網頁設計,決定了客戶是否繼續瀏覽的意願。台北網動廣告製作的RWD網頁設計,採用精簡與質感的CSS語法,提升企業的專業形象與簡約舒適的瀏覽體驗,讓瀏覽者第一眼就愛上它。
我們的窗體大小默認是288*512,其中鳥的速度在-20到10之間(最小速度我並不知道,但是經過觀察,並沒有小於-20的情況,而最大的速度在源代碼裏面已經說明好了為10)
Coding Time
在前面我們說,通過getGameState()函數,我們可以獲得幾個關於環境的數據,在這裏我們選擇如下的數據:
- next_pipe_dist_to_player:
- player_y與next_pipe_top_y的差值
- 的速度
但是我們可以想一想,next_pipe_dist_to_player一共會有多少種的取值:因為窗體大小為288*512,則取值的範圍大約是0~288,也就是說它大約有288個取值,而關於player_y與next_pipe_top_y的差值,則大概有1024個取值。這樣很難讓模型收斂,因此我們將數值進行簡化。其中簡化的思路來自:GitHub
首先我們創建一個Agent類,然後逐漸向裏面添加功能。
class Agent():
def __init__(self, action_space):
# 獲得遊戲支持的動作集合
self.action_set = action_space
# 創建q-table
self.q_table = np.zeros((6, 6, 6, 2))
# 學習率
self.alpha = 0.7
# 勵衰減因子
self.gamma = 0.8
# 貪婪率
self.greedy = 0.8
至於為什麼q-table的大小是(6,6,6,2),其中的3個6分別代表next_pipe_dist_to_player,player_y與next_pipe_top_y的差值,的速度,其中的2代表動作的個數。也就是說,表格中的state一共有$6 \times6 \times 6 $種,表格的大小為\(6 \times6 \times 6 \times 2\)。
縮小狀態值的範圍
我們定義一個函數get_state(s),這個函數專門提取遊戲中的狀態,然後返回進行簡化的狀態數據:
def get_state(self, state):
"""
提取遊戲state中我們需要的數據
:param state: 遊戲state
:return: 返回提取好的數據
"""
return_state = np.zeros((3,), dtype=int)
dist_to_pipe_horz = state["next_pipe_dist_to_player"]
dist_to_pipe_bottom = state["player_y"] - state["next_pipe_top_y"]
velocity = state['player_vel']
if velocity < -15:
velocity_category = 0
elif velocity < -10:
velocity_category = 1
elif velocity < -5:
velocity_category = 2
elif velocity < 0:
velocity_category = 3
elif velocity < 5:
velocity_category = 4
else:
velocity_category = 5
if dist_to_pipe_bottom < 8: # very close or less than 0
height_category = 0
elif dist_to_pipe_bottom < 20: # close
height_category = 1
elif dist_to_pipe_bottom < 50: # not close
height_category = 2
elif dist_to_pipe_bottom < 125: # mid
height_category = 3
elif dist_to_pipe_bottom < 250: # far
height_category = 4
else:
height_category = 5
# make a distance category
if dist_to_pipe_horz < 8: # very close
dist_category = 0
elif dist_to_pipe_horz < 20: # close
dist_category = 1
elif dist_to_pipe_horz < 50: # not close
dist_category = 2
elif dist_to_pipe_horz < 125: # mid
dist_category = 3
elif dist_to_pipe_horz < 250: # far
dist_category = 4
else:
dist_category = 5
return_state[0] = height_category
return_state[1] = dist_category
return_state[2] = velocity_category
return return_state
更新Q-table
更新的數學公式如下:
\[{\displaystyle Q^{new}(s_{t},a_{t})\leftarrow \underbrace {Q(s_{t},a_{t})} _{\text{舊的值}}+\underbrace {\alpha } _{\text{學習率}}\cdot \overbrace {{\bigg (}\underbrace {\underbrace {r_{t}} _{\text{獎勵}}+\underbrace {\gamma } _{\text{獎勵衰減因子}}\cdot \underbrace {\max _{a}Q(s_{t+1},a)} _{\text{estimate of optimal future value}}} _{\text{new value (temporal difference target)}}-\underbrace {Q(s_{t},a_{t})} _{\text{舊的值}}{\bigg )}} ^{\text{temporal difference}}} \]
下面是更新Q-table的函數代碼:
def update_q_table(self, old_state, current_action, next_state, r):
"""
:param old_state: 執行動作前的狀態
:param current_action: 執行的動作
:param next_state: 執行動作后的狀態
:param r: 獎勵
:return:
"""
next_max_value = np.max(self.q_table[next_state[0], next_state[1], next_state[2]])
self.q_table[old_state[0], old_state[1], old_state[2], current_action] = (1 - self.alpha) * self.q_table[
old_state[0], old_state[1], old_state[2], current_action] + self.alpha * (r + next_max_value)
選擇最佳的動作
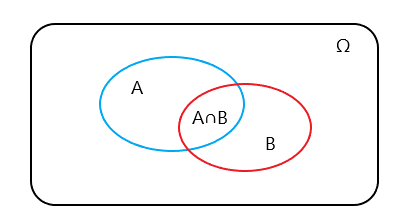
然後我們就是根據q-table對應的Q值選擇最大的那一個,其中第一個代表(也就是0)跳躍,第2個代表不執行任何操作。
選擇的示意圖如下:
代碼如下所示:
def get_best_action(self, state, greedy=False):
"""
獲得最佳的動作
:param state: 狀態
:是否使用ϵ-貪婪法
:return: 最佳動作
"""
# 獲得q值
jump = self.q_table[state[0], state[1], state[2], 0]
no_jump = self.q_table[state[0], state[1], state[2], 1]
# 是否執行策略
if greedy:
if np.random.rand(1) < self.greedy:
return np.random.choice([0, 1])
else:
if jump > no_jump:
return 0
else:
return 1
else:
if jump > no_jump:
return 0
else:
return 1
更新\(\epsilon\)值
這個比較簡單,從前面的博客中,我們知道\(\epsilon\)是隨着訓練次數的增加而減少的,有很多種策略可以選擇,這裏乘以\(0.95\)吧。
def update_greedy(self):
self.greedy *= 0.95
執行動作
在官方文檔中,如果小鳥沒有死亡獎勵為0,越過一個管道,獎勵為1,死亡獎勵為-1,我們稍微的對其進行改變:
def act(self, p, action):
"""
執行動作
:param p: 通過p來向遊戲發出動作命令
:param action: 動作
:return: 獎勵
"""
# action_set表示遊戲動作集(119,None),其中119代表跳躍
r = p.act(self.action_set[action])
if r == 0:
r = 1
if r == 1:
r = 10
else:
r = -1000
return r
main函數
最後我們就可以執行main函數了。
if __name__ == "__main__":
# 訓練次數
episodes = 2000_000000
# 實例化遊戲對象
game = FlappyBird()
# 類似遊戲的一個接口,可以為我們提供一些功能
p = PLE(game, fps=30, display_screen=False)
# 初始化
p.init()
# 實例化Agent,將動作集傳進去
agent = Agent(p.getActionSet())
max_score = 0
for episode in range(episodes):
# 重置遊戲
p.reset_game()
# 獲得狀態
state = agent.get_state(game.getGameState())
agent.update_greedy()
while True:
# 獲得最佳動作
action = agent.get_best_action(state)
# 然後執行動作獲得獎勵
reward = agent.act(p, action)
# 獲得執行動作之後的狀態
next_state = agent.get_state(game.getGameState())
# 更新q-table
agent.update_q_table(state, action, next_state, reward)
# 獲得當前分數
current_score = p.score()
state = next_state
if p.game_over():
max_score = max(current_score, max_score)
print('Episodes: %s, Current score: %s, Max score: %s' % (episode, current_score, max_score))
# 保存q-table
if current_score > 300:
np.save("{}_{}.npy".format(current_score, episode), agent.q_table)
break
部分的訓練的結果如下:
總結
emm,說實話,我也不知道結果會怎麼樣,因為訓練的時間比較長,我不想放在我的電腦上面跑,然後我就放在樹莓派上面跑,但是樹莓派性能比較低,導致訓練的速度比較慢。但是,我還是覺得我的方法有點問題,get_state()函數中簡化的方法,我感覺不是特別的合理,如果各位有好的看法,可以在評論區留言哦,然後共同學習。
項目地址:https://github.com/xiaohuiduan/flappy-bird-q-learning
參考
- Use reinforcement learning to train a flappy bird NEVER to die
- PyGame-Learning-Environment
- https://github.com/BujuNB/Flappy-Brid-RL
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
以設計的實用美學觀點,規劃出舒適、美觀的視覺畫面,有效提昇使用者的心理期待,營造出輕鬆、愉悅的網站瀏覽體驗。