※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
節能減碳愛地球是景泰電動車的理念,是創立景泰電動車行的初衷,滿意態度更是服務客戶的最高品質,我們的成長來自於你的推薦。
一:Spring Data JPA簡介
Spring Data JPA 是 Spring 基於 ORM 框架、JPA 規範的基礎上封裝的一套JPA應用框架,可使開發者用極簡的代碼即可實現對數據庫的訪問和操作。它提供了包括增刪改查等在內的常用功能,且易於擴展!學習並使用 Spring Data JPA 可以極大提高開發效率!
Spring Data JPA 讓我們解脫了DAO層的操作,基本上所有CRUD都可以依賴於它來實現,在實際的工作工程中,推薦使用Spring Data JPA + ORM(如:hibernate)完成操作,這樣在切換不同的ORM框架時提供了極大的方便,同時也使數據庫層操作更加簡單,方便解耦
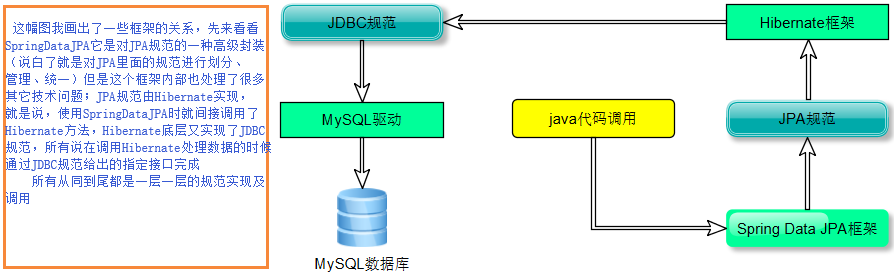
1:Spring Data JPA與JPA和hibernate三者關係
我在接下面的文章中都對它們三者進行擴展及應用,以及三者的封裝關係及調用關係,我下面也會以一張圖說明,如果此時有對JPA還一竅不通的可以參考我之前的一篇關於JPA文章的介紹
關係:其實看三者框架中,JPA只是一種規範,內部都是由接口和抽象類構建的;hibernate它是我們最初使用的一套由ORM思想構建的成熟框架,但是這個框架內部又實現了一套JPA的規範(實現了JPA規範定義的接口),所有也可以稱hibernate為JPA的一種實現方式我們使用JPA的API編程,意味着站在更高的角度上看待問題(面向接口編程);Spring Data JPA它是Spring家族提供的,對JPA規範有一套更高級的封裝,是在JPA規範下專門用來進行數據持久化的解決方案。
其實規範是死的,但是實現廠商是有很多的,這裏我對hibernate的實現商介紹,如其它的實現廠商大家可以自行去理解,因為規範在這,實現類可以更好別的,面向接口編程。
二:SpringDataJPA快速入門(完成簡單CRUD)
1:環境搭建及簡單查詢
-- 刪除庫
-- drop database demo_jpa;
-- 創建庫
create database if not exists demo_jpa charset gbk collate gbk_chinese_ci;
-- 使用庫
use demo_jpa;
-- 創建表
create table if not exists student(
sid int primary key auto_increment, -- 主鍵id
sname varchar(10) not null, -- 姓名
sage tinyint unsigned default 22, -- 年齡
smoney decimal(6,1), -- 零花錢
saddress varchar(20) -- 住址
)charset gbk collate gbk_chinese_ci;
insert into student values
(1,"螞蟻小哥",23,8888.8,"安徽大別山"),
(2,"王二麻",22,7777.8,"安徽大別山"),
(3,"李小二",23,6666.8,"安徽大別山"),
(4,"霍元甲",23,5555.8,null),
(5,"恭弘=叶 恭弘問",22,4444.8,"安徽大別山"),
(6,"李連傑",23,3333.8,"安徽大別山"),
(7,"馬克思",20,2222.8,"安徽大別山");
MySQL簡單建表語句 重要【後面都參照這個建表語句進行】
<dependencies> <!--單元測試坐標 4.12為最穩定--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <!--Spring核心坐標 注:導入此坐標也同時依賴導入了一些其它jar包--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.2.6.RELEASE</version> </dependency> <!--Spring對事務管理坐標--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-tx</artifactId> <version>5.2.6.RELEASE</version> </dependency> <!--Spring整合ORM框架的必須坐標 如工廠/事務等交由Spring管理--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-orm</artifactId> <version>5.2.6.RELEASE</version> </dependency> <!--Spring單元測試坐標--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>5.2.6.RELEASE</version> </dependency> <!--Spring Data JPA 核心坐標--> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-jpa</artifactId> <version>1.10.4.RELEASE</version> </dependency> <!--導入AOP切入點表達式解析包--> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> <version>1.9.5</version> </dependency> <!--Hibernate核心坐標--> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>5.4.10.Final</version> </dependency> <!--hibernate對持久層的操作坐標--> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>5.4.10.Final</version> </dependency> <!--這下面的2個el坐標是使用Spring data jpa 必須導入的,不導入則報el異常--> <dependency> <groupId>javax.el</groupId> <artifactId>javax.el-api</artifactId> <version>2.2.4</version> </dependency> <dependency> <groupId>org.glassfish.web</groupId> <artifactId>javax.el</artifactId> <version>2.2.4</version> </dependency> <!--C3P0連接池坐標--> <dependency> <groupId>c3p0</groupId> <artifactId>c3p0</artifactId> <version>0.9.1.2</version> </dependency> <!--MySQL驅動坐標--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.32</version> </dependency> <!--JAXB API是java EE 的API,因此在java SE 9.0 中不再包含這個 Jar 包。 java 9 中引入了模塊的概念,默認情況下,Java SE中將不再包含java EE 的Jar包 而在 java 6/7 / 8 時關於這個API 都是捆綁在一起的 拋出:java.lang.ClassNotFoundException: javax.xml.bind.JAXBException異常加下面4個坐標 --> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> <version>2.3.0</version> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.3.0</version> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-core</artifactId> <version>2.3.0</version> </dependency> <dependency> <groupId>javax.activation</groupId> <artifactId>activation</artifactId> <version>1.1.1</version> </dependency> </dependencies>
pom.xml坐標導入
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:jpa="http://www.springframework.org/schema/data/jpa" xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd"> <!--配置註解掃描--> <context:component-scan base-package="cn.xw"></context:component-scan> <!--配置C3P0連接池--> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <property name="driverClass" value="com.mysql.jdbc.Driver"></property> <property name="jdbcUrl" value="jdbc:mysql://localhost:3306/demo_jpa"></property> <property name="user" value="root"></property> <property name="password" value="123"></property> </bean> <!--創建EntityManagerFactory交給Spring管理,讓Spring生成EntityManager實體管理器操作JDBC--> <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> <!--配置一個連接池,後期獲取連接的Connection連接對象--> <property name="dataSource" ref="dataSource"></property> <!--配置要掃描的包,因為ORM操作是基於實體類的--> <property name="packagesToScan" value="cn.xw.domain"></property> <!--配置JPA的實現廠家 實現了JPA的一系列規範--> <property name="persistenceProvider"> <bean class="org.hibernate.jpa.HibernatePersistenceProvider"></bean> </property> <!--JPA供應商適配器 因為我上面使用的是hibernate,所有適配器也選擇hibernate--> <property name="jpaVendorAdapter"> <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"> <!--指定當前操作的數據庫類型 必須大寫,底層是一個枚舉類--> <property name="database" value="MYSQL"></property> <!--是否自動創建數據庫表--> <property name="generateDdl" value="false"></property> <!--是否在運行的時候 在控制台打印操作的SQL語句--> <property name="showSql" value="true"></property> <!--指定數據庫方言:支持的語法,如Oracle和Mysql語法略有不同 org.hibernate.dialect下面的類就是支持的語法--> <property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect"></property> <!--設置是否準備事務休眠會話的底層JDBC連接,即是否將特定於事務的隔離級別和/或事務的只讀標誌應用於底層JDBC連接。--> <property name="prepareConnection" value="false"></property> </bean> </property> <!--JPA方言:高級特性 我下面配置了hibernate對JPA的高級特性 如一級/二級緩存等功能--> <property name="jpaDialect"> <bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect"></bean> </property> <!--注入JPA的配置信息 加載JPA的基本配置信息和JPA的實現方式(hibernate)的配置信息 hibernate.hbm2ddl.auto:自動創建數據庫表 create:每次讀取配置文件都會創建數據庫表 update:有則不做操作,沒有則創建數據庫表 --> <property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">update</prop> </props> </property> </bean> <!--配置事務管理器 不同的事務管理器有不同的類 如我們當初使用這個事務管理器DataSourceTransactionManager--> <bean id="jpaTransactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"> <!--把配置好的EntityManagerFactory對象交由Spring內部的事務管理器--> <property name="entityManagerFactory" ref="entityManagerFactory"></property> <!--因為entityManagerFactory內部設置數據庫連接了 所有後面不用設置--> <!--<property name="dataSource" ref="dataSource"></property>--> </bean> <!--配置tx事務--> <tx:advice id="txAdvice" transaction-manager="jpaTransactionManager"> <tx:attributes> <tx:method name="save*" propagation="REQUIRED" read-only="false"/> <tx:method name="insert*" propagation="REQUIRED" read-only="false"/> <tx:method name="update*" propagation="REQUIRED" read-only="false"/> <tx:method name="delete*" propagation="REQUIRED" read-only="false"/> <tx:method name="get*" propagation="SUPPORTS" read-only="true"/> <tx:method name="find*" propagation="SUPPORTS" read-only="true"/> <tx:method name="*" propagation="SUPPORTS" read-only="true"/> <!--如果命名規範直接使用下面2行控制事務--> <!--<tx:method name="find*" propagation="SUPPORTS" read-only="true"/>--> <!--<tx:method name="*" propagation="REQUIRED" read-only="false"/>--> </tx:attributes> </tx:advice> <!--配置AOP切面--> <aop:config> <!--在日常業務中配置事務處理的都是Service層,因為這裡是案例講解,所有我直接在測試類進行 所有我把事務配置這,也方便後期拷貝配置到真項目中--> <aop:pointcut id="pt1" expression="execution(* cn.xw.service.impl.*.*(..))"/> <aop:advisor advice-ref="txAdvice" pointcut-ref="pt1"></aop:advisor> </aop:config> <!--整合SpringDataJPA--> <!--base-package:指定持久層接口 entity-manager-factory-ref:引用其實體管理器工廠 transaction-manager-ref:引用事務 --> <jpa:repositories base-package="cn.xw.dao" entity-manager-factory-ref="entityManagerFactory" transaction-manager-ref="jpaTransactionManager"></jpa:repositories> </beans>
applicationContext.xml 配置文件(重要)
@Entity @Table(name = "student") public class Student { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private Integer id; @Column(name = "sname") private String name; @Column(name = "sage") private Integer age; @Column(name = "smoney") private Double money; @Column(name = "saddress") private String address; //下面get/set/構造/toString都省略 //注意:我上面的都使用包裝類,切記要使用包裝類, // 原因可能數據庫某個字段查詢出來的值為空 null }
Student實體類及映射關係
//@Repository("studentDao") 這裏不用加入IOC容器 Spring默認幫我們注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> { /* JpaRepository<T,ID>:T:當前表的類型 ID:當前表主鍵字段類型 功能:用來完成基本的CRUD操作 ,因為內部定義了很多增刪改查操作 JpaSpecificationExecutor<T>:T:當前表的類型 功能:用來完成複雜的查詢等一些操作 */ }
StudentDao接口
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入數據 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Test public void test() { //查詢id為4學生 Student student = sd.findOne(4); System.out.println("開始打印:" + student); //開始打印:Student{id=4, name='霍元甲', age=23, money=5555.8, address='null'} } }
測試類
2:SpringDataJPA簡單單表接口方法查詢圖
3:針對上面圖的一些方法示例
在針對上面方法進行操作的時候,我們的Dao接口必須繼承JpaRepository<T,ID>和JpaSpecificationExecutor<T>(後面複雜查詢使用),大家也可以去研究一下CrudRepository類,這個類在這裏就不說了,JpaRespository類間接實現了它
①:Repository:最頂層的接口,是一個空的接口,目的是為了統一所有Repository的類型,且能讓組件掃描的時候自動識別。
②:CrudRepository :是Repository的子接口,提供CRUD的功能
③:PagingAndSortingRepository:是CrudRepository的子接口,添加分頁和排序的功能
④:JpaRepository:是PagingAndSortingRepository的子接口,增加了一些實用的功能,比如:批量操作等。
⑤:JpaSpecificationExecutor:用來做負責查詢的接口
⑥:Specification:是Spring Data JPA提供的一個查詢規範,要做複雜的查詢,只需圍繞這個規範來設置查詢條件
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入數據 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; /****************************查詢操作*****************************/ @Test //查詢並排序 public void findtestA() { //查詢全部 先對age排序后在進行id排序 Sort sort = new Sort(Sort.Direction.DESC, "age", "id"); List<Student> students = sd.findAll(sort); //打印省略 } @Test //查詢並分頁 public void findtestB() { //查詢分頁 page是第幾頁 size 每頁個數 當前是第2頁查詢3個 相當limit 6,3 Pageable pageable = new PageRequest(2, 3); Page<Student> page = sd.findAll(pageable); System.out.println("當前頁:"+page.getNumber()); System.out.println("每頁显示條目數:"+page.getSize()); System.out.println("總頁數:"+page.getTotalPages()); System.out.println("結果集總數量:"+page.getTotalElements()); System.out.println("是否是首頁:"+page.isFirst()); System.out.println("是否是尾頁:"+page.isLast()); System.out.println("是否有上一頁:"+page.hasPrevious()); System.out.println("是否有下一頁:"+page.hasNext()); System.out.println("結果集:"+page.getContent()); /* 當前頁:2 每頁显示條目數:3 總頁數:3 結果集總數量:7 是否是首頁:false 是否是尾頁:true 是否有上一頁:true 是否有下一頁:false 結果集:[Student{id=7, name='馬克思', age=20, money=2222.8, address='安徽大別山'}] */ //總結:以後做分頁操作變容易了呀 } @Test //查詢指定學生 public void findtesC() { //創建一個集合 List就是一個Iterable可迭代容器對象,因為實現了Iterable接口 List<Integer> list = new ArrayList<Integer>() {{ add(1);add(5);add(3); }}; List<Student> students = sd.findAll(list); //打印省略 } /****************************更新操作*****************************/ @Test //更新多個學生 更新學生全部地址為 安徽合肥 @Transactional @Rollback(value = false) public void savetestA() { //創建2個集合 第一個集合查詢全部數據,然後把集合里對象地址改為新的放入新集合上,後面迭代更新 List<Student> list = sd.findAll(); System.out.println(list.size()); List<Student> newlist = sd.findAll(); for (int i = 0; i < list.size(); i++) { Student student = list.get(i); student.setAddress("安徽合肥"); System.out.println(student); newlist.add(student); } List<Student> save = sd.save(newlist); //打印略 } /****************************刪除操作*****************************/ @Test //刪除指定學生 public void deletetest() { List<Integer> list = new ArrayList<Integer>() {{ add(1);add(5);add(3); }}; List<Student> all = sd.findAll(list); sd.deleteInBatch(all); } /** * 刪除方法介紹: * void deleteAll():底層會一條一條刪除 * void delete(Iterable<? extends T> entities):底層會一條一條刪除 * void deleteAllInBatch():底層會生成一個帶or語句刪除 * void deleteInBatch(Iterable<T> entities):底層會生成一個帶or語句刪除 * 如:Hibernate: delete from student where sid=? or sid=? or sid=? */ }
針對圖上面的一些方法操作
提取注意點:【添加/更新/查詢單個】
①:查詢單個getOne/findOne 【延遲加載/立即加載】
@Test //查詢單個 立即加載 public void findOneTest(){ Student student = sd.findOne(3); System.out.println("-------分割線-------"); System.out.println("打印對象:"+student); //控制台打印: /* Hibernate: select student0_.sid as sid1_0_0_, student0_.saddress as saddress2_0_0_, student0_.sage as sage3_0_0_, student0_.smoney as smoney4_0_0_, student0_.sname as sname5_0_0_ from student student0_ where student0_.sid=? 【SQL語句】 -------分割線------- 打印對象:Student{id=3, name='李小二', age=23, money=6666.8, address='安徽大別山'} */ //說明:在一執行到方法時就會去數據庫查詢,然後把數據封裝到實體類對象上 //底層調用: EntityManager裏面的find()方法 } @Test //查詢單個 懶加載【延遲加載】 @Transactional //此包下import org.springframework.transaction.annotation.Transactional; public void getOneTest(){ Student student=sd.getOne(3); System.out.println("-------分割線-------"); System.out.println("打印對象:"+student); //控制台打印 /* -------分割線------- Hibernate: select student0_.sid as sid1_0_0_, student0_.saddress as saddress2_0_0_, student0_.sage as sage3_0_0_, student0_.smoney as smoney4_0_0_, student0_.sname as sname5_0_0_ from student student0_ where student0_.sid=? 打印對象:Student{id=3, name='李小二', age=23, money=6666.8, address='安徽大別山'} */ //說明:在執行到getOne方法時並不會去數據庫查詢數據,而只是把此方法交給了代理對象,在後面 // 某個代碼要對查詢的對象student操作時才會去數據庫做真正查詢 //底層調用:EntityManager裏面的getReference方法 }
getOne【延遲加載】/findOne【立即加載】
這裏說明一下:在使用延遲加載的時候必須在方法上面加事務註解
②:添加/更新操作
@Test //添加 @Transactional //開啟事務 @Rollback(value = false) //不自動回滾 public void savetestA(){ //注意這裏 我調用了一個不帶 ID的構咋函數 Student student=new Student("蒼井空",25,555.6,"日本東京"); Student save = sd.save(student); System.out.println("添加的數據是:"+save); } @Test //更新 public void updatetestA(){ //更新操作的時候 首先要知道更新的ID 后通過把數據全部查詢出來,然後再通過set方法修改 Student student = sd.findOne(5); //查詢 student.setName("小次郎"); student.setAddress("日本"); //更新 Student save = sd.save(student); System.out.println("更新后的數據是:"+save); } /** * 總結:更新/添加都是save * 區別:傳入帶ID的屬性就是更新 不傳入ID屬性就是添加 * 注意:添加必須添加事務和回滾機制 */
更新/添加
綜上總結:在了解了前面的一些簡單的增刪改查,它都是內部提供好的方法(前提實現指定接口),可以滿足我們開發的大部分需求,可是多表查詢、多條件查詢等等是系統沒有定義的,接下來我和大家介紹一下複雜的查詢及動態查詢等等
三:SpringDataJPA的複雜自定義CRUD操作
1:使用JPQL語法進行操作(寫接口方法)
其實我們在使用SpringDataJPA提供的方法就可以解決大部分需求了,但是對於某些業務來說是要有更複雜的查詢及操作,這裏我就要使用自定義接口和註解@Query來完成JPQL的一系列操作,關於JPQL操作我在JPA的一章已經說過大概了
//@Repository("studentDao") //這裏不用加入IOC容器 Spring默認幫我們注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> { //查詢全部 根據年齡和地址查詢 @Query("from Student where age=?1 and address=?2") List<Student> findByAgeAndAddress(Integer age,String address); //查詢全部 根據姓名模糊查詢 @Query("from Student where name like ?1") List<Student> findByLikeName(String name); //查詢全部 根據地址為空的返回 @Query("from Student where address is null ") List<Student> findByAddressIsNull(); //查詢全部學生零花錢大於平均零花錢的所有學生 @Query("from Student where money > (select avg(money) from Student)") List<Student> findByMoneyBigAvgMoney(); //查詢零花錢在某個範圍內並且降序 @Query("from Student where money between ?1 and ?2 order by money desc") List<Student> findByMoneyBetweenToOrderBy(Integer begin ,Integer end); //查詢全部個數 @Query("select count(id) from Student") Long totalCount(); /*********************刪改操作************************/ //根據姓名刪除 @Query("delete from Student where name=?1") @Modifying void deleteByName(String name); //更新數據 @Query("update Student set name=?2 , address=?3 where id=?1") @Modifying void updateNameAndAddressById(Integer id,String name,String address); }
使用JPQL自定義方法完成刪改查 【普通常用】
@Test @Transactional @Rollback(value = false) public void test() { //裏面調用JPQL自定義的刪改操作 } 說明: 在使用@Query註解裏面定義的JPQL語法時 查詢不需要事務支持,但是刪改必須有事務及回滾操作,
而且在定義JPQL語句下面要註明@Modify代表是刪改 JPQL 裏面不存在添加insert操作,所有大家要添加操作的話 調用原來存在的方法
//@Repository("studentDao") //這裏不用加入IOC容器 Spring默認幫我們注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> { //使用排序 地址模糊查詢后 再按照id降序排列 @Query("from Student where address like ?1 ") List<Student> findByLikeAddressOrderById(String address, Sort sort); //使用命名參數 查詢年齡和地址模糊查詢 @Query("select s from Student as s where address like :address and age=:age") List<Student> findByLikeAddressAndAge(@Param(value="age") Integer s_age,@Param("address") String s_address); } /***下面測試方法****/ @Test //查詢學生帶排序 public void test() { //說在前面:Sort如果不指定DESC或者ASC 如 new Sort("id");說明默認對id ASC升序排列 //設置id為DESC降序排列 Sort sort = new Sort(Sort.Direction.DESC, "id"); List<Student> students = sd.findByLikeAddressOrderById("%大%", sort); //打印略 } @Test //使用命名參數 public void testA() { List<Student> students = sd.findByLikeAddressAndAge(23, "%大別山%"); //打印略 }
使用JPAL查詢 【其它查方式】
2:使用原生SQL語句進行操作(寫接口方法)
這種寫SQL語句的在SpringDataJPA中並不常用,因為SpringDataJPA對封裝性那麼高,而且是ORM思想,有各種方法及JPQL語句支持,所有我們本地SQL查詢也只要了解會用即可,SQL語句和我們平常寫的都一樣
//@Repository("studentDao") //這裏不用加入IOC容器 Spring默認幫我們注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> { //查詢指定的年齡和地址 @Query(value = "select * from student where sage=?2 and saddress=?1",nativeQuery = true) List<Student> findByAgeAndAddress(String address,Integer age); }
3:方法命名規則查詢
在Spring Data JPA裏面有一種很不錯的操作,那就是在接口中定義方法而不用實現也不用註解就可以實現其查詢操作,但是寫方法名查詢是有一套規範的,這裏我在官方文檔裏面整理出來了分享給大家【注意:方法名命名規則不能對其增加(insert)和修改(update)】
①:方法名查詢的具體規則
//示例場景 //當前域為Student 就是對Student上註解了@Entity,表示對於ORM思想它是一張表 //Student域屬性有name、age、address、dog //dog裏面又是一個封裝類 封裝了Dog的一些屬性如 name、color等 ①:按照Spring data的定義規則,查詢的方法必須為【find/findBy/read/readBy/get/getBy】六種方式開頭,後面則寫條件屬性關鍵字,條件屬性的 首字母必須大寫,因為框架在進行方法名解析的時候,會把方法名前面多餘的前綴截取掉,然後對剩下的進行解析 例: 截取前:getByNameAndAge 截取后:NameAndAge 截取前:findByAddressLikeAndAge 截取后:AddressLikeAndAge 截取前:findByDogName 截取后:DogName 問題:findByNameOrderByDesc 這種最後攜帶一個 OrderByDesc 排序的怎麼辦呢? 其實最後面攜帶這種對數據進行最後的排序等等操作,框架會對其另外拆分 ②:對已經分割好的方法名如 ‘DogName’ ,根據POJO規範會把首字母變為小寫 ‘dogName’,然後用 ‘dogName’這個屬性去Student域里 面查詢是否存在此屬性,如果是裏面的某個屬性則進行查詢。 ③:如果查詢不到此屬性,則會對‘dogName’從右向左來截取,截取到從右向左的第一個大寫字母(所有截取到了Name),然後框架會把剩下 的字符‘dog’去Student域裏面查詢,找到此屬性則查詢,沒有會重複前面的截取操作,(重要步驟) ④:現在框架提取到了到了‘dog’,然後去Student域查詢到了,則表示方法最終是根據Student.dog.name方式進行查詢,假設name屬性後面 還是一個封裝類,框架會一直截取,根據③方式截取。 注意:在寫上面這類方法名是,而且查詢的裏面會有一層一層的封裝類,所有強烈建議使用findByDog_Name();
②:注意一些細節(必看)
1:查詢的條件為null時 實體介紹:Student裡面包含 address為String類型 age為Integer類型 查詢方法定義:List<Student> findByAddressAndAge(String address, Integer age); 調用時傳入值:List<Student> students = sd.findByAddressAndAge(null,23); 後台生成的SQL:where (student0_.saddress is null) and student0_.sage=? 結論:當我們傳入了一個null值時,表示會去查詢數據庫中address中字段為null的數據其實在編寫此代碼傳入null值以為會跳過此判斷, 但是恰恰相反,框架會去查詢為null的數據。(實現此方式的只能去動態查詢,這種簡單的查詢不能滿足要求) 2:排序功能 List<Student> findByAddressOrderByAge(String address); //名稱正序(正序時,推薦此方式,簡單) List<Student> findByAddressOrderByAgeAsc(String address); //名稱正序(效果同上) List<Student> findByAddressOrderByAgeDesc(String address); //名稱倒序 3:限定查詢結果集大小 ①:Student findFirstByOrderByAgeAsc(); ②:Student findTopByOrderByAgeAsc(); 說明:對錶的全部數據根據age進行Asc(升序)排序后再選擇第一條數據返回 相應SQL:select .... from student student0_ order by student0_.sage asc limit ? (這裡是limit 1) 注意但是我如果寫出:List<Student> findTop3ByOrderByAgeAsc(); 則就是每次返回3條 limit 3 ③:List<Student> findFirst2ByAddress(String address,Sort sort); ④:List<Student> findTop2ByAddress(String address,Sort sort); 說明:首先進行數據查詢並通過Sort進行排序后 再篩選數據列表中最前面的2行數據返回 limit 2 ⑤:Page<Student> queryFirst2ByAddress(String address, Pageable pageable) ⑥:List<Student> queryFirst2ByAddress(String address, Pageable pageable) 說明:首先進行數據查詢 查詢全部指定的address後進行分頁,分頁完後進行數據控制 控制說明:關於帶分頁的控制是,假設分頁過後查詢的數據id為3,4,5 查詢出這三條數據後進行數據控制, 本案例是控製為2條,那返回的id數據就是3,4兩條記錄,id為5的就捨棄,那麼如果數據控制是5條, 那麼就會打印3,4,5另外再去添加6,7補充數據長度 總結:這裏的這裏的First和Top意思相同都是最前面,query也和find一樣; 關於一個小點: Page<Student> students = sd.queryFirst1ByAddress("安徽大別山",new PageRequest(1,2)); 這裏我是返回分頁后的第一條數據,可是返回了分頁數據的前一個,分頁后id是3,4控制數據后First1 返回了id為2 4:計數 返回總數 Long countByAddress(String address); 5:刪除 void deleteByAddress(String address); //或 void removeByAddress(String address); 說明:必須添加事務和回滾,這樣根據條件找到幾條就刪幾條 @Test @Transactional @Rollback(value=false) public void test() { sd.deleteByAddress("安徽大別山"); } //對應的SQL語句 //Hibernate: select .... from student student0_ where student0_.saddress=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=?
一些注意事項及其它操作
③:列舉幾個常用的方法定義查詢
//根據地址查詢後進行姓名模糊匹配 List<Student> findByAddressAndNameLike(String address ,String likeName); //查詢指定範圍類的個數 List<Student> countByAgeBetween(Integer ... arg); //根據對應的Address查詢后對查詢出的數據根據age排序后返回第一條數據 Student findFirstByAddressOrderByAgeDesc(String address);
四:SpringDataJpa的源碼快速分析
通過前幾節的增刪改查大家會發現,我們不用寫Dao接口實現類而是繼承JpaRepository和JpaSpecificationExcutor這兩個接口就能夠保證正常的增刪改查功能,這是為什麼呢?
//@Repository("studentDao") //這裏不用加入IOC容器 Spring默認幫我們注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> {}
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入數據 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; //這裏注入進去的數據又是誰呢? @Test public void testA(){ //查詢單個 Student one = sd.findOne(2); System.out.println(one); } }
其實不難想象,但凡是憑空就可以注入對象的,這內部肯定用到了JDK動態代理,那JDK代理類又是誰呢?經過debug發現是JdkDynamicAopProxy
final class JdkDynamicAopProxy implements AopProxy, InvocationHandler, Serializable {
....//這個類實現了InvocationHandler 那必然有invoke方法,這裏面是操作該生成哪個代理對象返回 }
所有說在那個注入的時候,Spring AOP就是通過JdkDyynamicAopProxy類幫我們實現的,那這個代理類最終創建的代理返回的對象又是誰呢?
那我們再去查看一下SimpleJpaRepository類,肯定是實現了我們自己接口繼承的2個類,而且也有許多的操作方法的實現
@Repository @Transactional(readOnly = true) public class SimpleJpaRepository<T, ID extends Serializable> implements JpaRepository<T, ID>, JpaSpecificationExecutor<T> {
.....
}
總結:就是通過Jdk動態代理生成一個對象返回注入后,我們就可以調出各種操作方法
五:SpringDataJpa動態查詢
在日常編程中往往是查詢某個實體的時候,給定的條件是不固定的,那我們在不固定查詢條件的情況下就在Dao編寫查詢方法嗎?這顯然是不可取的,只要在確定及肯定會用到這個查詢條件后才會去Dao編寫此查詢方法;那麼在查詢不固定的情況下我們就會用到Specification動態查詢,要想使用動態查詢的話必須在當前使用的Dao接口下繼承JpaSpecificationExecutor接口;在使用動態查詢對比JPQL,其動態查詢是類型安全,更加面向對象。
/** * ①:JpaSpecificationExecutor: * 用來做動態查詢的接口 * ②:Specification: * 是Spring Data JPA提供的一個查詢規範,要做複雜的查詢,只需圍繞這個規範來設置查詢條件。 * JpaSpecificationExecutor接口下一共就5個接口方法 * 有查詢單個、查詢全部、查詢全部【分頁】、查詢全部【排序】、統計總數 */ public interface JpaSpecificationExecutor<T> { T findOne(Specification<T> spec); List<T> findAll(Specification<T> spec); Page<T> findAll(Specification<T> spec, Pageable pageable); List<T> findAll(Specification<T> spec, Sort sort); long count(Specification<T> spec); }
1:常用查詢(簡單)
①:Root<X> 接口 此接口是代表查詢根對象,可以獲取實體類中的屬性 如:root.get("name"); 獲取了實體類的name屬性 ②:CriteriaBuilder 接口 此接口用來構建查詢,此對象裏面有許多查詢條件方法 方法名稱 Sql對應關係 equle filed = value gt(greaterThan ) filed > value lt(lessThan ) filed < value ge(greaterThanOrEqualTo ) filed >= value le( lessThanOrEqualTo) filed <= value notEqule filed != value like filed like value notLike filed not like value 注:其實這裏面還有許多的查詢條件方法如求平均值啦查詢指定範圍等等
①:根據某個字段查詢單個數據
//查詢單個 @Test public void testB() { // Specification:查詢條件設置 Specification<Student> spe = new Specification<Student>() { //實現接口的方法 關於Root、CriteriaBuilder上面有介紹 public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { //獲取實體屬性name Path<Object> name = root.get("name"); //根據指定的姓名查詢 Predicate select = cb.equal(name, "螞蟻小哥"); //返回一定是Predicate類型 return select; } }; //查詢單個 Student student = sd.findOne(spe); System.out.println(student); }
②:多條件查詢、模糊查詢等一些操作
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
搬家費用:依消費者運送距離、搬運樓層、有無電梯、步行距離、特殊地形、超重物品等計價因素後,評估每車次單
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入數據 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Test //多條件查詢 public void testC() { //根據年齡和地址查詢 Specification<Student> spe=new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { Path<Object> age = root.get("age"); Path<Object> address = root.get("address"); Predicate p1 = cb.equal(age, "23"); Predicate p2 = cb.equal(address, "安徽大別山"); Predicate select = cb.and(p1, p2); return select; } }; List<Student> students = sd.findAll(); //打印略 } @Test //查詢多個條件 public void testD(){ //根據精準地址和模糊姓名查詢 List<Student> students = sd.findAll(new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { Path<Object> address = root.get("address"); Path<Object> name = root.get("name"); Predicate p1 = cb.equal(address, "安徽大別山"); Predicate p2 = cb.like(name.as(String.class), "李%"); return cb.and(p1,p2); } }); //注!!!:在使用gt、lt、ge、le、like等條件方法查詢的時候需要告知傳入的屬性的class屬性 //如:cb.like(name.as(String.class), "李%"); //打印略 } @Test //查詢全部為指定住址的學生帶年齡排序 public void testE(){ List<Student> students = sd.findAll(new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { return cb.equal(root.get("address"), "安徽大別山"); } }, new Sort(Sort.Direction.DESC, "age")); } @Test //查詢全部帶分頁 public void testF(){ Page<Student> students = sd.findAll(new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { return null; //return null 代表沒條件查詢全部 } }, new PageRequest(2, 2)); } }
分頁、排序、多條件
2:複雜查詢(了解)
我們在之前使用過了Root和CriteriaBuilder的2個接口,可是裏面還有一個參數,是CriteriaQuery接口,它代表一個頂層查詢條件,用來自定義查詢,操作頂層查詢可以使我們更靈活,但是在靈活的基礎上又多了一絲絲複雜
@Test //多條件查詢 public void testC() { //根據年齡和地址查詢 Specification<Student> spe=new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { Path<Object> age = root.get("age"); Path<Object> address = root.get("address"); Predicate p1 = cb.equal(age, "23"); Predicate p2 = cb.equal(address, "安徽大別山"); //query內部提供了一些連接用的如where 、having、groupBy.... query.where(cb.and(p1,p2)); return query.getRestriction(); } }; List<Student> students = sd.findAll(); System.out.println(students); //打印略 }
六:多表操作(一對一)了解
補充:多表操作的 一對一、多對一(一對多)、多對多
1:確定多表之間的關係: 一對一和一對多: 一的一方稱為主表,而多的一方稱為從表,外鍵就要建立在從表上,它們的取值的來源主要來自主鍵 多對多: 這個時候需要建立一个中間表,中間表中最少由2個字段組成,這2個字段作為外鍵指向2張表的主鍵又組成了聯合主鍵 2:配置多表聯繫註解介紹 @OneToOne(一對一) @ManyToOne(多對一) @OneToMany(一對多) @ManyToMany(多對多) 內部參數: cascade:配置級聯操作 CascadeType.ALL:所有 CascadeType.MERGE:更新 CascadeType.PERSIST:保存 CascadeType.REMOVE:刪除 fetch:配置延遲加載和立即加載 FetchType.EAGER 立即加載 FetchType.LAZY 延遲加載 mappedBy:放棄外鍵維護 3:配置外鍵關係的註解 @JoinColumn(定義主鍵字段和外鍵字段的對應關係) 內部參數: name:外鍵字段的名稱 referencedColumnName:指定引用主表的主鍵字段名稱 unique:是否唯一。默認值不唯一 nullable:是否允許為空。默認值允許。 insertable:是否允許插入。默認值允許。 updatable:是否允許更新。默認值允許。 columnDefinition:列的定義信息。 @JoinTable(針對中間表的設置) 內部參數: name:配置中間表的名稱 joinColumns:中間表的外鍵字段關聯當前實體類所對應表的主鍵字段 inverseJoinColumn:中間表的外鍵字段關聯對方表的主鍵字段
在多表操作中、一對一併不是我們掌握的重點,因為在開發中最多的還是使用一對多(多對一)和多對多,廢話不多說,我先來和大家說說一對一的具體操作步驟吧!
我們在開始使用多表操作的時候,要對原來的部分代碼進行改造,建議大家搭建一個全新的項目,具體的代碼我已經在最上面的入門案例中給出了,只要在新項目中導入相應的坐標和配置文件即可,然後修改配置文件裏面的具體數據庫和數據庫密碼即可,還有就是現在的建表語句和上面的全部操作不太一樣,為了更好的演示一對一的操作我這邊準備了一個數據庫建表語句,下面的表含義是,每個學生表(student)都有一條家庭(family)的登記的記錄表,為一對一關係(理想化表,雙胞胎除外)
-- 一對一關係 -- 刪除庫 drop database demo_jpa_one_one; -- 創建庫 create database if not exists demo_jpa_one_one charset gbk collate gbk_chinese_ci; -- 使用庫 use demo_jpa_one_one; # 家庭表創建 create table if not exists family( fid int(11) primary key auto_increment, -- 家庭主鍵 fmember int(11) not null, -- 成員個數 fguardian varchar(10) not null, -- 監護人 ftel char(11) not null, -- 監護人號碼 fdad varchar(10), -- 爸爸姓名 fmom varchar(10), -- 媽媽姓名 faddress varchar(20) -- 家庭詳細地址 )charset gbk; # 創建學生表 create table if not exists student ( sid int(11) primary key auto_increment, -- 編號 sname varchar(5) not null, -- 姓名 ssex enum('男','女') default '男', -- 性別 sage tinyint(11) unsigned not null default 20, -- 年齡 smoney decimal(4,1) default 0, -- 零花錢 最高999.9 saddress varchar(10), -- 住址 senrol date default '0000-00-00', -- 入學時間 f_id int(11), -- 連接家庭id foreign key(f_id) references family(fid) -- 連接家庭id主鍵 )charset gbk; # 添加家庭信息 insert into family(fmember,fguardian,ftel,fdad,fmom,faddress)values (0,"余蒙飄","","戚曦維","余蒙飄","安徽省六安市裕安區"), (0,"孫戀烈","","梁輪亭","孫戀烈","安徽省合肥市瑤海區"), (0,"張頻時","","張頻時","","安徽省安慶市宜秀區"), (0,"王京正","","王京正","梁晝庭","安徽省六安市金安區"), (0,"劉資納","","王諄斌","劉資納","安徽省滁州市全椒縣"), (0,"白飛解","","廖旺賜","白飛解","安徽省安慶市大觀區"), (0,"梁昀輝","","鄔國耿","梁昀輝","安徽省蚌埠市蚌山區"), (0,"古錄鋼","","","古錄鋼","安徽省滁州市定遠縣"), (0,"姬橋毅","","姬橋毅","寧竹熊","安徽省合肥市蜀山區"), (0,"劉始瑛","","劉始瑛","韋歡億","安徽省淮南市大通區"); # 添加學生數據 insert into student(sid,sname,saddress,f_id)values (1 ,"王生安","安徽六安",1 ),(2 ,"李鑫灝","安徽合肥",2 ), (3 ,"薛佛世","安徽蚌埠",3 ),(4 ,"蔡壯保","安徽安慶",4 ), (5 ,"錢勤堃","安徽合肥",5 ),(6 ,"潘恩依","安徽合肥",6 ), (7 ,"陳國柏","安徽六安",7 ),(8 ,"魏皚虎","安徽六安",8 ), (9 ,"周卓浩","安徽六安",9 ),(10,"湯辟邦","安徽六安",10); -- 更新數據 update student set ssex=ceil(rand()*2),sage=ceil(rand()*5+20),smoney=(rand()*999), senrol=concat(ceil(rand()*3+2017),'-' , ceil(rand()*12) , '-',ceil(rand()*20)); update family set ftel=concat(if(ceil(rand()*3)=1,if(ceil(rand()*3)=2,if(ceil(rand()*3)=1, if(ceil(rand()*3)=2,"155","166"),if(ceil(rand()*3)=3,"163","170")),"164"), if(ceil(rand()*3)=3,"188","176")),floor(rand()*90000000+9999999)),fmember=ceil(rand()*3+2); -- 查詢數據 show create table student\G show create table family\G select * from student; select * from family;
一對一 數據庫建表語句
其實我們並不需要創建數據庫表(數據庫必須創建),因為我們使用的是ORM思想的框架,說白了就是程序自動幫我們創建表(設置create配置),我們只需要關心實體類就可以了,這個實體類我也為大家準備好了
/** * 創建了一個Student的實體-表關係類 */ @Entity @Table(name = "student") public class Student { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private Integer id; @Column(name = "sname") private String name; @Column(name = "ssex") private String sex; @Column(name = "sage") private Integer age; @Column(name = "smoney") private Double money; @Column(name = "saddress") private String address; @Column(name = "senrol") private String enrol; //get/set/toString/無參有參構造器 大家自己創建 }
Student的Entity實體對象 未指定外鍵關係
/** * 創建了一個Family的實體-表關係類 */ @Entity @Table(name = "family") public class Family { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "fid") private Integer id; @Column(name = "fmember") private Integer member; @Column(name = "fguardian") private String guardian; @Column(name = "ftel") private String tel; @Column(name = "fdad") private String dad; @Column(name = "fmom") private String mom; @Column(name = "faddress") private String address; //get/set/toString/無參有參構造器 大家自己創建 }
Family的Entity實體對象 未指定外鍵關係
在準備好了映射關係之後,我們要創建StudentDao、FamilyDao這2個接口,並且分別繼承JpaRepository和JpaSpecificationExecutor這2個接口,完成了這些操作后就可以開始編寫測試類了
<!--大家把配置文件的JPA配置方式改為create每次都創建表--> <property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">create</prop> </props> </property>
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入數據 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Autowired @Qualifier(value = "familyDao") private FamilyDao fd; @Test //完成保存操作 @Transactional @Rollback(value = false) public void testC() { Student stu=new Student("王二","男",26,666.3,"安徽六安","2020-6-5"); Family fam=new Family(3,"王二牛","17688888888","王二牛","母老虎","安徽六安裕安區白嫖村"); //開始保存 sd.save(stu); fd.save(fam); } }
如果不出意外,大家可能會遇到一個異常,這正是我想和大家說的,具體說明在文章最後的【關於多表操作異常】問題總結和大家說明一下,我們解決問題后回來再次運行后,控制台會打印2條建表語句和插入數據的語句,前面說過,這2張表是一個一對一的關聯關係,我們接下來就對這2張表建立關係。
建立關係 Student---Family (一對一) 為Student建立關聯到Family的關係(在Student中增加一個字段) @OneToOne(targetEntity = Family.class) @JoinColumn(name = "f_id", referencedColumnName = "fid") private Family family; 為Family建立關聯到Student的關係(在Family中增加一個字段) @OneToOne(targetEntity = Student.class) @JoinColumn(name = "f_id", referencedColumnName = "sid") private Student student; 這樣就完成了相互引用了,每個實體類都擁護一個對方實體,完成了一對一的關聯
完成了關聯后我們對測試方法進行改造
@Test //多條件查詢 @Transactional @Rollback(value = false) public void testC() { Student stu = new Student("王二", "男", 26, 666.3, "安徽六安", "2020-6-5"); Family fam = new Family(3, "王二牛", "17688888888", "王二牛", "母老虎", "安徽六安裕安區白嫖村"); //通過set方法分別設置對應的字段,使其關聯 stu.setFamily(fam); fam.setStudent(stu); sd.save(stu); fd.save(fam); }
運行後會自動幫我們創建2張表並且設置外鍵
mysql> select * from student; +-----+----------+------+----------+--------+-------+------+------+ | sid | saddress | sage | senrol | smoney | sname | ssex | f_id | +-----+----------+------+----------+--------+-------+------+------+ | 1 | 安徽六安 | 26 | 2020-6-5 | 666.3 | 王二 | 男 | 1 | +-----+----------+------+----------+--------+-------+------+------+ mysql> select * from family; +-----+----------------------+--------+-----------+---------+--------+-------------+------+ | fid | faddress | fdad | fguardian | fmember | fmom | ftel | f_id | +-----+----------------------+--------+-----------+---------+--------+-------------+------+ | 1 | 安徽六安裕安區白嫖村 | 王二牛 | 王二牛 | 3 | 母老虎 | 17688888888 | 1 | +-----+----------------------+--------+-----------+---------+--------+-------------+------+
發現自動幫我們創建的表會有2個外鍵,可是這2個外鍵是多餘的,我們這個時候需要放棄外鍵維護,按照之前的一對一建表語句說明,外鍵是建立在學生表上的,通過學生表上面的外鍵來尋找到家庭表的信息,這個時候我們在家庭表上面放棄外鍵維護
//@OneToOne(targetEntity = Student.class) //@JoinColumn(name = "f_id", referencedColumnName = "sid") //引用對方的字段 @OneToOne(mappedBy = "family") private Student student;
1:一對一的對象導航查詢
<property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">update</prop> <!--設置數據庫方言--> <prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop> </props> </property>
@Test //多條件查詢 @Transactional @Rollback(value = false) public void testC() { System.out.println(sd.findOne(1)); //我們要編寫toString方法后才可以打印全部 }
七:多表操作(一對多/多對一)重點
其實一對多和多對一本質上是一樣的,只是順序發生了變化,我就詳細的把一對多給講一下,在這裏我已經有過一個數據庫建表語句,但是因為是ORM項目,我們建表語句是由程序幫我們自動創建的,之所以我編寫了SQL語句是為了方便後期查詢練習
#### 一對多 這裏我使用的關係是一個老師對應多個學生,一個學生對應一個老師 #### 老師表為主表、學生表為從表 #### 一對多 -- 刪除庫 drop database demo_jpa_one_many; -- 創建庫 create database if not exists demo_jpa_one_many charset gbk collate gbk_chinese_ci; -- 使用庫 use demo_jpa_one_many; -- 創建主表 (輔導員表) create table if not exists teacher( tid int primary key, -- 編號 tname varchar(5) not null, -- 姓名 tsex enum('男','女') default '男', -- 性別 tage tinyint unsigned, -- 年齡 tsalary decimal(6,1) default 0, -- 工資 最高99999.9 taddress varchar(10) -- 住址 )charset gbk collate gbk_chinese_ci; -- 創建從表 (學生表) create table if not exists student ( sid int(11) primary key auto_increment, -- 編號 sname varchar(5) not null, -- 姓名 ssex enum('男','女') default '男', -- 性別 sage tinyint(11) unsigned not null default 20, -- 年齡 smoney decimal(4,1) default 0, -- 零花錢 最高999.9 saddress varchar(10), -- 住址 senrol date default '0000-00-00', -- 入學時間 tid int , -- 連接老師id foreign key(tid) references teacher(tid) -- 連接老師主鍵 )charset gbk; -- 添加老師數據 insert into teacher (tid,tname,taddress)values (1,'張老師','江蘇南京'), (2,'李老師','江蘇無錫'), (3,'王老師','江蘇常熟'); -- 添加學生數據 insert into student(sid,sname,saddress)values (1 ,"王生安","安徽六安"),(2 ,"李鑫灝","安徽合肥"), (3 ,"薛佛世","安徽蚌埠"),(4 ,"蔡壯保","安徽安慶"), (5 ,"錢勤堃","安徽合肥"),(6 ,"潘恩依","安徽合肥"), (7 ,"陳國柏","安徽六安"),(8 ,"魏皚虎",null); -- 數據更新 update teacher set tsex=ceil(rand()*2),tage=ceil(rand()*10+25),tsalary=ceil(rand()*3000+8000); update student set ssex=ceil(rand()*2),sage=ceil(rand()*5+20),smoney=(rand()*999), senrol=concat(ceil(rand()*3+2017),'-' , ceil(rand()*12) , '-',ceil(rand()*20)),tid=ceil(rand()*3);
一對多 關係建表建庫語句
此時的一對多關係是【一個老師有多個學生】,反之,如果是多對一隻需要調換關係即可,2者差不多,我就針對這個一對多講解;在編寫程序之前我們必須要搞明白什麼是主表和從表的關係,這影響到我們後面編寫一對多的關係:
主表:
由主鍵和其它字段組成,後期由其它表參照當前表主鍵,此時的表為主表,
在其它表中如果引用主表的主鍵字段,那麼主表的主鍵被引用后將不能隨意更改,
如果強制更改則必須設置級聯操作(cascade)
從表:
由主鍵、外鍵和其它字段組成,後期由本表的外鍵字段去引用其它帶有主鍵的表,一旦其它的
表主鍵被引用后,被引用的表則被稱為主表,反之引用其它表主鍵的表被稱之從表
一句話概括:有外鍵字段的表是從表(排除其它複雜表,因為有的表即引用其它別也被其它表引用)
在我們了解了上面的關係后,我們就可以搭建操作一對多的環境了,首先我們就是要準備建造一個數據庫(不是數據表)名稱為demo_jpa_one_many,因為這個框架只要編寫好映射關係後會自動幫我們創建表的;現在建立一個項目,只需要在空項目導入pom.xml坐標和配置外鍵(配置文件一定要修改正確數據庫連接),我將帶大家一步一步完成一對多操作,如果這些都會直接跳過;完成了上面的操作后,我們首先就是要去編寫實體類及映射關係:
/** * 創建了一個Teacher的實體-表關係類 * 在案例中 當前老師表為主表 */ @Entity @Table(name = "teacher") public class Teacher { //創建主鍵字段和普通字段 @Id @Column(name = "tid") private Integer id; @Column(name = "tname") private String name; @Column(name = "tsex") private String sex; @Column(name = "tage") private Integer age; @Column(name = "tsalary") private Double salary; @Column(name = "taddress") private String address; //省略 get/set/有參無參構造器 }
老師表映射關係 主表
/** * 創建了一個Student的實體-表關係類 * 在案例中 當前學生表為從表 */ @Entity @Table(name = "student") public class Student { //創建主鍵字段和普通字段 @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private Integer id; @Column(name = "sname") private String name; @Column(name = "ssex") private String sex; @Column(name = "sage") private Integer age; @Column(name = "smoney") private Double money; @Column(name = "saddress") private String address; @Column(name = "senrol") private String enrol; //省略 get/set/有參無參構造器 }
學生表映射關係 從表
在完成上面的一些操作后,大家已經完成了實體類及映射的創建,這裏我沒有為這2張表建立外鍵關係,因為在沒接觸過多表操作的話冒然把映射一起寫完有可能會出現異常(肯定有人說,這咋這麼啰嗦呀)那好,對有操作的,只是複習怎麼使用的直接可以當cv攻城師複製即可;現在我們來編寫2個dao類
public interface StudentDao extends JpaRepository<Student,Integer>, JpaSpecificationExecutor<Student> { } public interface TeacherDao extends JpaRepository<Teacher,Integer> , JpaSpecificationExecutor<Teacher> { }
寫好以後就正式測試了,測試完成后大家會發現是2個沒有任何關係的2張獨立的表(如果出現異常了去下面查看異常講解)
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入數據 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Autowired @Qualifier(value="teacherDao") private TeacherDao td; @Test //多條件查詢 @Transactional @Rollback(value = false) public void testC() { Student student=new Student("張小三","男",25,222.3,"安徽六安","2018-8-8"); Teacher teacher=new Teacher(10,"張老師","男",35,9999.6,"北京順義"); //保存 td.save(teacher); sd.save(student); } }
測試代碼 創建2張表
mysql> select * from student; +-----+----------+------+----------+--------+--------+------+ | sid | saddress | sage | senrol | smoney | sname | ssex | +-----+----------+------+----------+--------+--------+------+ | 1 | 安徽六安 | 25 | 2018-8-8 | 222.3 | 張小三 | 男 | +-----+----------+------+----------+--------+--------+------+ mysql> select * from teacher; +-----+----------+------+--------+---------+------+ | tid | taddress | tage | tname | tsalary | tsex | +-----+----------+------+--------+---------+------+ | 10 | 北京順義 | 35 | 張老師 | 9999.6 | 男 | +-----+----------+------+--------+---------+------+
注:創建2表的聯繫
在創建2表的關係中,我們必須要分清主表和從表的關係,這樣才可以設計出一個完整的關係創建,具體的主表和從表上面以給出介紹
創建從表的關係連接(student) 在從表中添加一個引用teacher屬性,因為一個student中有一個teacher //創建外鍵字段 因為從表上有明確外鍵引用其它表 所以必須要有外鍵字段 @ManyToOne(targetEntity = Teacher.class) @JoinColumn(name="t_id",referencedColumnName = "tid") private Teacher teacher; 注: targetEntity = Teacher.class:當前引用的主表類型 name="t_id" 代表當前student表中的外鍵字段 referencedColumnName = "tid" 代表參照主表的哪個字段 建表樣式: mysql> select * from student; +-----+----------+------+----------+--------+--------+------+------+ | sid | saddress | sage | senrol | smoney | sname | ssex | t_id | +-----+----------+------+----------+--------+--------+------+------+ | 1 | 安徽六安 | 25 | 2020-6-6 | 666.3 | 李小二 | 男 | 100 | +-----+----------+------+----------+--------+--------+------+------+ ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 創建主表的關係連接(teacher) 在主表中添加一個引用student的屬性,因為一個teacher中有多個student //創建外鍵字段 這裡是主表,所以主動放棄外鍵維護 //@OneToMany(targetEntity = Student.class) //@JoinColumn(name = "s_id",referencedColumnName = "sid") //引用從的外鍵字段 @OneToMany(mappedBy = "teacher") private Set<Student> students=new HashSet<Student>(); 注: mappedBy = "teacher" :代表參照對方表 假設主表不放棄外鍵維護就會出現下面情況: mysql> select * from teacher; +-----+----------+------+--------+---------+------+------+ | tid | taddress | tage | tname | tsalary | tsex | s_id | +-----+----------+------+--------+---------+------+------+ | 100 | 北京順義 | 32 | 王老師 | 6666.6 | 男 | 1 | +-----+----------+------+--------+---------+------+------+ 問題所在:這時候主表引用從表,而從表也引用主表,這顯然不是一個合格設計 解決后:在主表上設置的放棄外鍵維護,並參照從表的關係 mysql> select * from teacher; +-----+----------+------+--------+---------+------+ | tid | taddress | tage | tname | tsalary | tsex | +-----+----------+------+--------+---------+------+ | 100 | 北京順義 | 32 | 王老師 | 6666.6 | 男 | +-----+----------+------+--------+---------+------+
創建測試,在測試的時候大家把配置文件的配置改為create,代表每次執行都會創建表
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入數據 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Autowired @Qualifier(value="teacherDao") private TeacherDao td; @Test //多條件查詢 @Transactional @Rollback(value = false) public void testC() { //創建2個對象 Student student=new Student("李小二","男",25,666.3,"安徽六安","2020-6-6"); Teacher teacher=new Teacher(100,"王老師","男",32,6666.6,"北京順義"); //把老師放入學生數據中 把學生數據放入老師表中 student.setTeacher(teacher); teacher.getStudents().add(student); //保存 這裏注意一下,因為我的teacher主鍵不是自動生成 , // 所以先保存teacher才可以保存student,因為teacher主鍵不是自動生成,直接先保存student會無法獲取teacher主鍵 td.save(teacher); sd.save(student); } }
測試方法
然後會生成和我給出的創建sql語句生成的相同的字段,並且外鍵也是可以的,如果出現異常,大家檢查一下get/set/無參構造/有參構造,這裏的無參構造必須存在,否則真的會異常
1:級聯操作
級聯操作分級聯刪除、級聯添加、級聯更新,如果設置了級聯操作就可以完成級聯操作,具體的在一對一上的補充介紹了
@OneToMany(mappedBy = "teacher",cascade = CascadeType.ALL) private Set<Student> students=new HashSet<Student>();
在主表上設置了級聯操作(ALL=全部都支持),只要保存teaccher就會級聯着保存student
@Test //多條件查詢 @Transactional @Rollback(value = false) public void testC() { //創建2個對象 Student student=new Student("李小二","男",25,666.3,"安徽六安","2020-6-6"); Teacher teacher=new Teacher(100,"王老師","男",32,6666.6,"北京順義"); //把老師放入學生數據中 把學生數據放入老師表中 student.setTeacher(teacher); teacher.getStudents().add(student); //直接添加老師就可以保存雙方數據 td.save(teacher); }
2:查詢數據
這個時候我們導入之前的sql語句,然後把配置改為update,每次執行,有表則不創建表,
@Test //多條件查詢 @Transactional //必須添加事務 public void testC() { Teacher teacher = td.findOne(2); System.out.println(teacher); }
八:多表操作(多對多)
多對多是一個雙向關係,我首先來展示一下SQL語句
##### 多對多 -- 刪除庫 drop database demo_jpa_many_many; -- 創建庫 create database if not exists demo_jpa_many_many charset gbk collate gbk_chinese_ci; -- 使用庫 use demo_jpa_many_many; -- 創建從表 (學生表) create table if not exists student ( sid int(11) primary key auto_increment, -- 編號 sname varchar(5) not null, -- 姓名 ssex enum('男','女') default '男', -- 性別 sage tinyint(11) unsigned not null default 20, -- 年齡 smoney decimal(4,1) default 0, -- 零花錢 最高999.9 saddress varchar(10), -- 住址 senrol date default '0000-00-00' -- 入學時間 )charset gbk; # 學生社團組織 create table if not exists organization( oid int(11) primary key auto_increment, -- 社團主鍵id oname varchar(10) not null unique -- 社團名稱 )charset gbk; # 中間表 社團和學生對應多對多關係 create table if not exists student_organization( soid int(11) primary key auto_increment, -- 中間表id s_id int(11), -- 學生id o_id int(11), -- 社團id foreign key(s_id) references student(sid), -- 連接學生id foreign key(o_id) references organization(oid) -- 連接社團id )charset gbk; # 添加學生社團組織學習 insert into organization (oname) values ("書法協會"),("法律協會"),("武術協會"), ("魔術社團"),("網球協會"),("啦啦隊團"); -- 添加學生數據 insert into student(sid,sname,saddress)values (1 ,"王生安","安徽六安"),(2 ,"李鑫灝","安徽合肥"), (3 ,"薛佛世","安徽蚌埠"),(4 ,"蔡壯保","安徽安慶"), (5 ,"錢勤堃","安徽合肥"),(6 ,"潘恩依","安徽合肥"), (7 ,"陳國柏","安徽六安"),(8 ,"魏皚虎",null); # 添加學生和社團的中間表 insert into student_organization(s_id,o_id) values (1,1),(1,3),(1,2),(1,6),(2,5),(2,1),(2,2), (6,6),(6,2),(6,4),(6,3),(7,4),(7,2);
多對多建表語句
上面多對多關係是一個學生可以加入多個社團(組織),一個組織可以有多名學生,間就構建成多對多關係,廢話不多說,直接上映射關係
在創建映射關係的時候我們得確定哪一方會放棄外鍵維護權, 在多對多的時候我們通常放棄的被動的一方 @Entity @Table(name = "student") public class Student { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private Integer id; @Column(name = "sname") private String name; @Column(name = "ssex") private String sex; @Column(name = "sage") private Integer age; @Column(name = "smoney") private Double money; @Column(name = "saddress") private String address; @Column(name = "ssenrol") private String senrol; // @ManyToMany(targetEntity = Organization.class) // @JoinTable(name = "student_organization", // joinColumns = {@JoinColumn(name = "s_id", referencedColumnName = "sid")} , // inverseJoinColumns = {@JoinColumn(name = "o_id", referencedColumnName = "oid")} // ) @ManyToMany(mappedBy = "students") private Set<Organization> organizations = new HashSet<Organization>(); } @Entity @Table(name = "organization") public class Organization { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "oid") private Integer id; @Column(name = "oname") private String name; @ManyToMany(targetEntity = Student.class) @JoinTable(name = "student_organization", joinColumns ={@JoinColumn(name = "o_id",referencedColumnName = "oid")} , inverseJoinColumns = {@JoinColumn(name = "s_id",referencedColumnName = "sid")} ) private Set<Student> students=new HashSet<Student>(); }
多表映射關係
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Autowired @Qualifier(value = "organizationDao") private OrganizationDao od; @Test @Transactional @Rollback(value = false) public void fun() { Student student=new Student("張三","男",45,555.6,"安徽六安","2012-8-8"); Organization o=new Organization("魔術社"); student.getOrganizations().add(o); o.getStudents().add(student); od.save(o); sd.save(student); } }
測試環境
九:對象導航查詢
在一對多查詢的時候,多的一方數據會有延遲加載,但是對於一對一查詢的時候數據會有立即加載
十:關於多表操作異常
1:關於hibernate數據庫方言問題(dialect)
6月 03, 2020 4:57:00 下午 org.hibernate.dialect.Dialect <init> INFO: HHH000400: Using dialect: org.hibernate.dialect.MySQLDialect 省去部分... Hibernate: create table family (...) type=MyISAM //上面一局為我們創建的是一張表並設置MyISAM引擎 錯誤就在這 無法運行了 6月 03, 2020 4:57:01 下午 org.hibernate.tool.schema.internal.ExceptionHandlerLoggedImpl handleException WARN: GenerationTarget encountered exception accepting command : Error executing DDL "create table family (...) type=MyISAM" via JDBC Statement org.hibernate.tool.schema.spi.CommandAcceptanceException: Error executing DDL "create table family (...) type=MyISAM" via JDBC Statement //從上面錯誤可以看出 程序運行的時候默認的數據庫方言設置了 org.hibernate.dialect.MySQLDialect 而這個默認是MyISAM引擎
問題所在:因為我導入的hibernate坐標是5.4.10.Final,在導入這類高版本的坐標往往要為數據庫方言設置MySQL5InnoDBDialect的配置,在我前面也測試了,關於坐標版本問題,發現5.0.x.Final左右的版本不用設置數據庫方言,默認即可。
<property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">create</prop> <!--設置數據庫方言--> <prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop> </props> </property>
具體的版本在創建數據庫表的時候會拋各種異常,這裏我整理了一下數據庫方言,方便大家參考
<property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">create</prop> <!--設置數據庫方言--> <prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop> </props> </property> <!--數據庫方言--> DB2 org.hibernate.dialect.DB2Dialect DB2 AS/400 org.hibernate.dialect.DB2400Dialect DB2 OS390 org.hibernate.dialect.DB2390Dialect PostgreSQL org.hibernate.dialect.PostgreSQLDialect MySQL org.hibernate.dialect.MySQLDialect MySQL with InnoDB org.hibernate.dialect.MySQLInnoDBDialect MySQL with MyISAM org.hibernate.dialect.MySQLMyISAMDialect Oracle (any version) org.hibernate.dialect.OracleDialect Oracle 9i/10g org.hibernate.dialect.Oracle9Dialect Sybase org.hibernate.dialect.SybaseDialect Sybase Anywhere org.hibernate.dialect.SybaseAnywhereDialect Microsoft SQL Server org.hibernate.dialect.SQLServerDialect SAP DB org.hibernate.dialect.SAPDBDialect Informix org.hibernate.dialect.InformixDialect HypersonicSQL org.hibernate.dialect.HSQLDialect Ingres org.hibernate.dialect.IngresDialect Progress org.hibernate.dialect.ProgressDialect Mckoi SQL org.hibernate.dialect.MckoiDialect Interbase org.hibernate.dialect.InterbaseDialect Pointbase org.hibernate.dialect.PointbaseDialect FrontBase org.hibernate.dialect.FrontbaseDialect Firebird org.hibernate.dialect.FirebirdDialect
數據庫方言 hibernate.dialect
2:關於對象導航查詢異常
WARNING: Please consider reporting this to the maintainers of org.springframework.data.projection.DefaultMethodInvokingMethodInterceptor WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release Hibernate: sql語句 java.lang.StackOverflowError at java.base/java.lang.AbstractStringBuilder.inflate(AbstractStringBuilder.java:202) at java.base/java.lang.AbstractStringBuilder.putStringAt(AbstractStringBuilder.java:1639) at java.base/java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:513) .......
關以這種錯誤大多都是編寫的toString語句發生了錯誤,大家在寫toString的時候一定要分清主表和從表,在編寫主表的toString的時候一定要去除外鍵字段,而在編寫從表的時候一定要加上外鍵字段,因為平時我們都是通過從表查詢數據(因為從表有指向主表的外鍵),這樣可以把主表的數據通過外鍵查詢出來,但是主表上如果也有從表的字段的話就會一隻循環,數據沒完沒了,所有拋異常也是對的,
總結一句話,從表有主表的字段,主表有從表的字段,打印從表順帶打印主表,但是主表裡面還有從表字段,然後繼續打印從表字段…….
3:關於延遲加載事務問題
org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: cn.xw.domain.Teacher.students, could not initialize proxy - no Session at org.hibernate.collection.internal.AbstractPersistentCollection.throwLazyInitializationException(AbstractPersistentCollection.java:606) at org.hibernate.collection.internal.AbstractPersistentCollection.withTemporarySessionIfNeeded(AbstractPersistentCollection.java:218) at org.hibernate.collection.internal.AbstractPersistentCollection.initialize(AbstractPersistentCollection.java:585) at org.hibernate.collection.internal.AbstractPersistentCollection.read(AbstractPersistentCollection.java:149) at org.hibernate.collection.internal.PersistentSet.toString(PersistentSet.java:327) at java.base/java.lang.String.valueOf(String.java:2801) at java.base/java.lang.StringBuilder.append(StringBuilder.java:135)
關於在使用延遲加載的時候,在當前的方法上必須設置@Transactional,因為在使用延遲加載底層已經使用了事務的相關方法
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
透過選單樣式的調整、圖片的縮放比例、文字的放大及段落的排版對應來給使用者最佳的瀏覽體驗,所以不用擔心有手機版網站兩個後台的問題,而視覺效果也是透過我們前端設計師優秀的空間比例設計,不會因為畫面變大變小而影響到整體視覺的美感。