拜占庭將軍問題
我們已知的共識算法,Paxos、Raft解決的都是非拜占庭問題,也就是可以容忍節點故障,消息丟失、延時、亂序等,但節點不能有惡意節點。但如何在有惡意節點存在的情況下達成共識呢?BFT共識算法就是解決這一問題的。即不但能容忍節點故障,還能容忍一定的惡意節點或者說拜占庭節點的存在。我們下面就學習一下BFT算法中的PBFT(Practical Byzantine Fault Tolerance)。BFT算法有非常多的變種,這裏只學習PBFT,其他的可以舉一反三。
PBFT
PBFT核心由3個協議組成:一致性協議、檢查點協議、視圖更換協議。系統正常運行在一致性協議和檢查點協議下,只有當主節點出錯或者運行緩慢的情況下才會啟動視圖更換協議,以維持系統繼續響應客戶端的請求。下面詳解這3個子協議。在講一致性協議之前,我們屏蔽算法細節先看一下正常情況下大致是怎麼工作的,大致流程如下:
- 客戶端發送請求給主節點(如果請求發送給了從節點,從節點會將該請求轉發給主節點或者將主節點的信息告知客戶端,讓客戶端發送給主節點)。
- 主節點將請求廣播給從節點。
- 主從節點經過2輪投票后執行客戶端的請求並響應客戶端。(協議細節見下面的一致性協議)
- 客戶端收集到來着\(f+1\)個不同節點的相同的響應后,確認請求執行成功。(因為最多有\(f\)個惡意節點,\(f+1\)個相同即能保證正確性)。
一致性協議
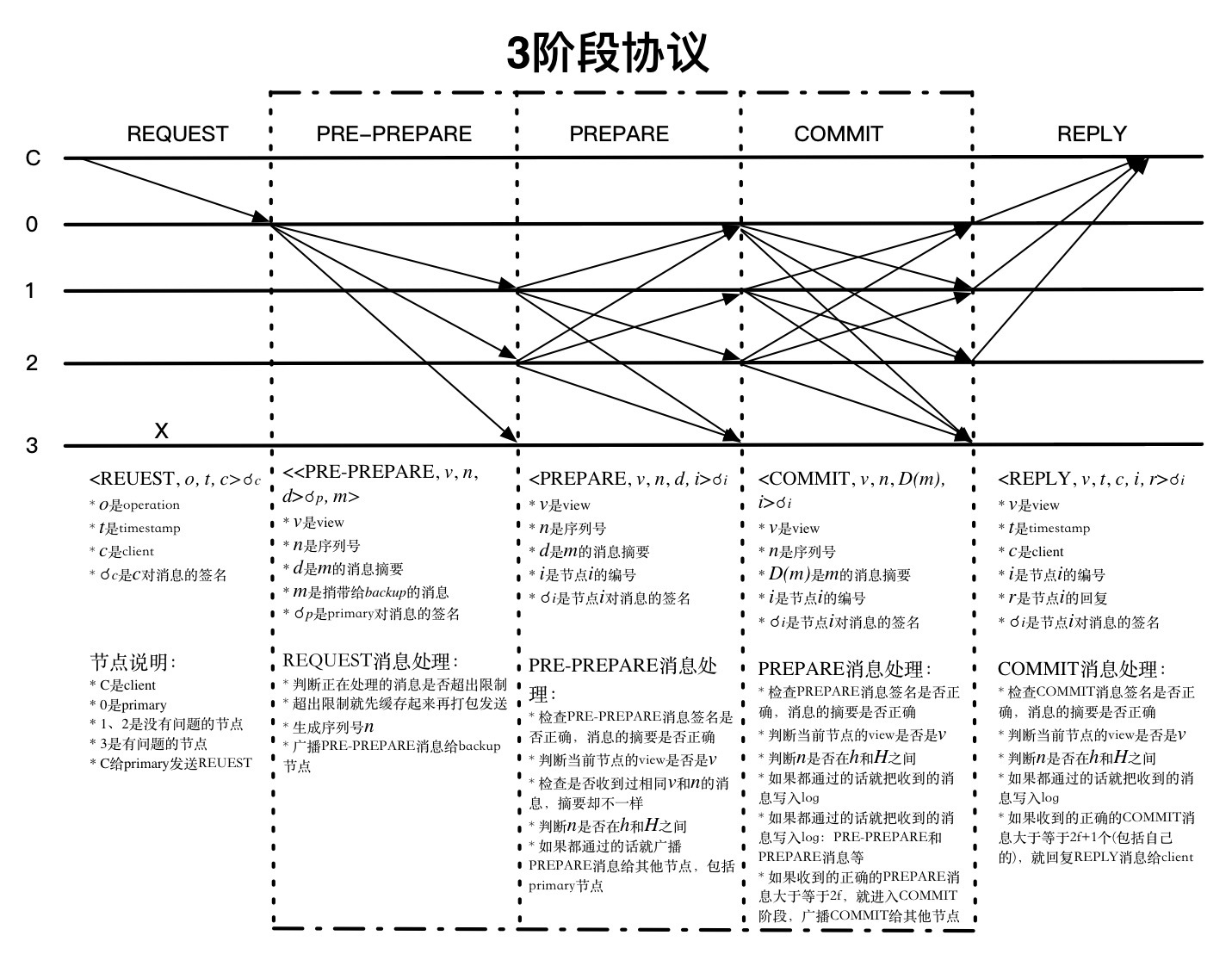
一致性協議的目標是使來自客戶端的請求在每個服務器上都按照一個確定的順序執行。 在協議中,一般有一個服務器被稱作主節點,負責將客戶端的請求排序;其餘的服務器稱作從節點,按照主節點提供的順序執行請求。所有的服務器都在相同的配置信息下工作,這個配置信息稱作視圖view,每更換一次主節點,視圖view就會隨之變化。協議主要分pre-prepare、prepare、commit三階段,如下圖所示:
REQUEST:
首先是客戶端發起請求, 請求<REQUEST,o,t,c>中時間戳t主要用來保證exactly-once語義,也就是說對同一客戶端請求不能有執行2次的情況,具體實現時也不一定非是時間戳,也可以是邏輯時鐘或者其他,只要能唯一標識這個請求就可以了。
PRE-PREPARE:
【1】 收到客戶端的請求消息后,先判斷當前正在處理的消息數量是否超出限制,如果超出限制,則先緩存起來,後面再打包一起處理。否則的話(當然,沒超過也可以緩存處理),對請求分配序列號n,並附加視圖號v等信息生成PRE-PREPARE消息<<PRE-PREPARE,v,n,d>,m>,廣播給其他節點。簡而言之就是對請求分配序號並告知所有節點。
【2】 收到PRE-PREPARE的消息後進行如下處理:
- 消息合法性檢查,消息簽名是否正確,消息摘要是否正確。
- 視圖檢查,檢查是否是同一個視圖號
v。 - 水線檢查,判斷
n是否在h和H之間。(h一般是系統穩定檢查點,H是上限,會隨着h的不斷提高而提高)
如果都通過的話,就廣播PREPARE消息<PREPARE,v,n,d,i>給其他節點,表示自己收到並認可[n,v]這個請求,進入prepare階段。如果沒有通過,則忽略該消息。
這裏想一個問題,從節點能不能收到PRE-PREPARE消息就執行請求呢?答案顯然是不能的,因為不能確認本節點與其他節點收到的是相同的請求消息,此時不能確定主節點是不是正常節點,如果主節點是惡意節點呢?比如,發送給從節點1的消息是m,而發送給從節點2的消息是m',如果直接執行就會出現從節點的不一致。因為不能確認本節點與其他節點收到的是相同的請求消息,所以要通過從節點與從節點交互的方式互相告知收到了請求消息,好讓後面階段對比一下,是否一致。
PREPARE:
收到PREPARE消息<PREPARE,v,n,d,i>后,進行如下處理:
- 消息合法性檢查,消息簽名是否正確,消息摘要是否正確。
- 視圖檢查,檢查是否是同一個視圖號
v。 - 水線檢查,判斷
n是否在h和H之間。
如果上面都通過,就將PREPARE消息加入到日誌中,並繼續收集PREPARE消息,如果收到正確的\(2f\)張(包括自己)PREPARE消息,這裏如何驗證是否正確呢?主要是收到的PREPARE要與PRE-PREPARE中的v、n、d等信息要匹配,就進入COMMIT階段,廣播COMMIT消息<COMMIT,v,n,D(m),i>。
這一階段一般也可以稱為第一輪投票,目的是什麼呢?論文中是這麼說的:The pre-prepare and prepare phases of the algorithm guarantee that non-faulty replicas agree on a total order for the requests within a view. 濃縮為兩個字就是定序,確定在同一視圖下足額的正常的節點都對來自客戶端的請求有相同的定序。再說的直白點,就是解決上面提到的,無法確認本節點與其他節點收到的消息是否一致的問題。通過檢查相同視圖號v及同一序號n下的消息摘要d是否一致來判斷同一視圖配置下的同一個序號請求的消息是否一致。同時也確保了有足夠數量的節點收到了一致的消息請求。
可以再想一個問題,此時可以直接執行請求嗎?答案是不可以,因為此時,你只能確認自己收到了\(2f\)個一致的PREPARE消息,你無法確認其他節點是否也收到了\(2f\)個一致的PREPARE消息。也就是說,當前,你只能確認自己準備好了去執行序號為n的請求,但是你不能確認其他節點有沒有準備好,所以,還要再進行一次節點間的消息交互,互相告訴大家,我準備好了。
COMMIT:
在上一階段,節點收到足額PREPARE投票後會廣播COMMIT投票,過程類似,當節點收到其他節點的COMMIT投票消息后,會進行如下檢查:
- 消息合法性檢查,檢查消息簽名是否正確,消息摘要正不正確有沒有被篡改。
- 視圖檢查,view是否匹配。
- 水線檢查,判斷
n是否在h和H之間。
如果都通過則把收到的投票消息寫入日誌log中,如果收到的合法的COMMIT投票消息大於等於\(2f+1\)個(包括自己),意思就是,已經確認大多數節點都準備好了執行請求,就執行請求並回復REPLY消息給客戶端。這裏如同上面一樣,也是檢查視圖,序號及消息是否匹配。
REPLY:
客戶端收到REPLY后,會進行統計,如果收到\(f+1\)個相同時間戳t和響應值r,則認為請求響應成功。如果在規定的時間內沒有收到回應或者沒有收到足額回應怎麼辦?可以將該請求廣播給所有節點,節點收到請求后,如果該請求已經被狀態機執行了,則再次回復客戶端REPLY消息,如果沒有被狀態機執行,如果節點不是主節點,就將該請求轉發給主節點。如果主節點沒有正常的將該請求廣播給其他節點,則將會被懷疑是主節點故障或惡意節點,當有足夠的節點都懷疑時將會觸發視圖變更協議,更換視圖。
我們進行進一步的分析,可以看到,如果是客戶端沒有收到任何回應,很有可能是主節點故障或主節點是惡意節點(我就故意不執行你的請求),沒有將請求足額廣播給其他節點,(當然還有消息丟失等原因,這裏不在詳細分析),這時,客戶端因一直沒有響應,所以將請求廣播給了所有節點,所有節點收到請求后,轉發給主節點后發現主節點怎麼什麼都不幹呀,懷疑主節點有問題,然後觸發視圖更換協議,換掉主節點。當然,客戶端沒有收到足額回應的一個原因還可能是消息丟失,那麼如果是已經執行了該請求的節點再次收到該請求後會再次回應REPLY,前提是該請求是在水線範圍內的合法請求,否則被拒絕。
檢查點協議
在上面的一致性協議中可以看到,系統每執行一個請求,服務器都需要記錄日誌(包括,request、pre-prepare、prepare、commit等消息)。如果日誌得不到及時的清理,就會導致系統資源被大量的日誌所佔用,影響系統性能及可用性。另一方面,由於拜占庭節點的存在,一致性協議並不能保證每一台服務器都執行了相同的請求,所以,不同服務器狀態可能不一致。例如,某些服務器可能由於網絡延時導致從某個序號開始之後的請求都沒有執行。因此,設置周期性的檢查點協議,將系統中的服務器同步到某一個相同的狀態。簡言之,主要作用有2個:1、同步服務器的狀態;2、定期清理日誌。
同步服務器的狀態,比較容易理解與做到。比如在區塊鏈系統中,同步服務器的狀態,實際上就是追塊,即服務器節點會通過鏈定時廣播的鏈世界狀態或其他消息獲知到自己區塊落後了,然後啟動追塊流程。
定期清理日誌,怎麼做呢?首先要明確哪些日誌可以被清理,哪些日誌仍然需要保留。如果一個請求已經被\(f+1\)台非拜占庭節點執行,並且某一服務器節點i可以向其他服務器節點證明這一點,那麼該i節點就可以將關於這個請求的日誌刪除。協議一般採用的方式是服務器節點每執行一定數量的請求就將自己的狀態發送給所有服務器並且執行一個該協議,如果某台服務器節點收到\(2f+1\)台服務器節點的狀態,那麼其中一致的部分就是至少有\(f+1\)台非拜占庭服務器節點經歷過的狀態,因此,這部分的日誌就可以刪除,同時更新為較新狀態。
具體實現時可以聯想到上面的一致性協議總的水線檢查。上面的低水線h值等同於穩定檢查點,穩定檢查點之前的日誌都可被清理掉。高水線H=h+k,也就是接收請求序號上限值,因為穩定檢查點往往是間隔很多的序號才觸發一次,所以k一般要設置的足夠大。例如,每間隔100個請求就觸發一次檢查點協議,提升水線,k可以設置為200。
這裏解釋一下穩定檢查點的概念,可以理解為當\(2f+1\)個節點都達到了某個請求序號,該請求序號就是穩定檢查點。所有穩定檢查點之前的消息都可以被丟棄,減少資源佔用。 對比Raft,Raft是通過快照的方式壓縮日誌,都需要一個清理日誌的機制,不然日誌無限增長下去會造成系統不可用
視圖更換協議
在一致性協議里,已經知道主節點在整個系統中擁有序號分配,請求轉發等核心能力,支配着這個系統的運行行為。然而一旦主節點自身發生錯誤,就可能導致從節點接收到具有相同序號的不同請求,或者同一個請求被分配多個序號等問題,這將直接導致請求不能被正確執行。視圖更換協議的作用就是在主節點不能繼續履行職責時,將其用一個從節點替換掉,並且保證已經被非拜占庭服務器執行的請求不會被篡改。即,核心有2點:1,主節點故障時,可能造成系統不可用,要更換主節點;2,當主節點是惡意節點時,要更換為誠實節點,不能讓作惡節點作為主節點。
當檢測到主節點故障或為惡意節點觸發視圖更換時,下一任主節點應該選誰呢?PBFT的辦法是採用“輪流上崗”的方式,通過\((v+1) \ mod \ N\),其中\(v\)為當前視圖號,\(N\)為節點總數,通過這一方式確定下一個視圖的主節點。還有個更關鍵的問題,什麼時候觸發視圖更換協議呢?我們繼續往下討論。
如果是主節點故障的情況,這種情況一般較好處理。具體實現時,一般從節點都會維護一個定時器,如果長時間沒有收到來自主節點的消息,就會認為主節點發生故障。此時可觸發視圖更換協議,當然具體實現時,細節可能會不同,比如,也可以是這種情況,客戶端發送請求給故障主節點必然導致長時間收不到響應,所以,客戶端將請求發送給了系統中所有從節點,從節點將請求轉發給主節點並啟動定時器,如果主節點長時間沒有將該請求分配序號發送PRE-PREPARE消息,認為主節點故障,觸發視圖更換協議。這2種情況比較好理解,但就這2種情況嗎?其實還有以下幾種情況也會觸發視圖更換協議:
- 從節點廣播
PREPARE消息后,在約定的時間內未收到來自其他節點的\(2f\)個一致合法消息。 - 從節點廣播
COMMIT消息后,在約定的時間內未收到來自其他節點的\(2f\)個一致合法消息。 - 從節點收到異常消息,比如視圖、序號一致,但消息不一致。
這三點,都有可能是主節點作惡導致的,但也有可能是消息丟失等原因導致的。雖然不一定是因為主節點異常導致的,但從另一個角度看,解決了從節點不能無限等待其他節點投票消息的問題。
這裏補充一點,觸發視圖更換協議后,將不再接收除檢查點消息、
VIEW-CHANGE消息、NEW-VIEW消息之外的消息。也就是視圖更換期間,不再接收客戶端請求,暫停服務。
解決了什麼時候觸發的問題后,下一個問題就是具體怎麼實現呢?當因上面的情況觸發視圖更換協議時,從節點i就會廣播一個VIEW-CHANGE消息<VIEW-CHANGE,v+1,n,C,P,i>,序號n是節點i的最新穩定檢查點s,C是\(2f+1\)個有效檢查點消息,是為了證明穩定檢查點s的正確性,P是位於序號n之後的一系列消息的結合,這裏要包含這些信息可以理解為是證據,也就是說,從節點不能隨便就發送一個VIEW-CHANGE,什麼證據都沒有,別人怎麼能認同你更換視圖呢?。上面我們提到過下一任主節點是誰的問題?通過\((v+1) \ mod \ N\)確定的一下任主節點p(在圖中就是節點1),在收到\(2f\)個有效的VIEW-CHANGE消息后,就廣播<NEW-VIEW,v+1,V,O>消息,這裏V和O具體的生成方法參考原論文,主要是VIEW-CHANGE和PRE-PREPARE等消息構成的集合,主要目的是為了讓從節點去驗證當前新的主節點的合法性以及解決下面這個問題,還有要處理未確認消息和投票消息。
視圖更換協議需要解決的問題是如何保證已經被非拜占庭服務器執行的請求不被更改。由於系統達成一致性之後至少有\(f+1\)台非拜占庭服務器節點執行了請求,所以目前採用的方法是:由新的主節點收集至少\(2f+1\)台服務器節點的狀態信息(也就是上面在構造消息時所需的各種消息集合),這些狀態信息中一定包含所有執行過的請求;然後,新主節點將這些狀態信息發送給所有的服務器,服務器按照相同的原則將在上一個主節點完成的請求同步一遍,同步之後,所有的節點都處於相同的狀態,這時就可以開始執行新的請求。
若干細節問題的思考
在3階段協議中,對收到的消息都要進行消息合法性檢查、視圖檢查、水線檢查這3項檢查,為什麼呢?
這3項檢查是十分有必要的,添加消息簽名是為了驗證投票是否合法,正確統計合法票數,不能是隨便一個不知道的節點都能投票,那我怎麼驗證到底是誰投的呀。也就是說,要通過消息簽名的方式確認消息來源,通過消息摘要的方式,確認消息沒有被篡改。當然,考慮到性能因素,也可以使用消息認證碼(MAC),以節省大量加解密的性能開銷。PBFT算法,可以容忍節點作惡,消息丟失、延時、亂序,但消息不能被篡改。
視圖檢查比較容易理解,所有節點必須在同一個配置下才能正常工作。如果節點的視圖配置不一致,比如主節點不一致、節點數量不一致,那統計合法票數的時候,真沒法幹了。
水線檢查,是檢查點協議的一部分,在工程實現時,不是所有的請求我都有處理,比如,你收到一個歷史投票信息,你還有必要處理嗎?當然,它的作用不止於此,還可以防止惡意節點選擇一個非常大的序列號而耗盡序列號空間,例如,當一個節點分配了超過H上限的序列號,這時,正常節點會拒絕這個請求從而阻止了惡意節點分配的遠超過H的序列號。
3階段協議中每一階段的意義是什麼?
論文中有如下錶述:
The three phases are pre-prepare, prepare, and commit.The pre-prepare and prepare phases are used to totally order requests sent in the same view even when the primary, which proposes the ordering of requests, is faulty. The prepare and commit phases are used to ensure that requests that commit are totally ordered across views.
即,pre-prepare和prepare階段,主要的作用就是定序,個人理解就是要確認有足夠數量的節點收到同一請求,並且與自己所收到的請求相一致。prepare以及commit階段是確認大家執行的同一請求。
為什麼是\(3f+1\)?
我們知道PBFT的容錯能力為不超過三分之一,即\(n=3f+1\),\(f\)為拜占庭節點數量。但這個公式是怎麼來的呢?論文中有這麼一段論述可以幫助我們去理解:
The resiliency of our algorithm is optimal: \(3f+1\) is the minimum number of replicas that allow an asynchronous system to provide the safety and liveness properties when up to \(f\) replicas are faulty. This many replicas are needed because it must be possible to proceed after communicating with \(n-f\) replicas, since \(f\) replicas might be faulty and not responding. However, it is possible that the \(f\) replicas that did not respond are not faulty and, therefore, \(f\) of those that responded might be faulty. Even so, there must still be enough responses that those from non-faulty replicas outnumber those from faulty ones, i.e., \(n-2f>f\). Therefore \(n>3f\).
意思就是,在一個容忍\(f\)個錯誤節點的系統中,系統至少要\(3f+1\)個節點才能保證系統安全可靠。為什麼呢?因為在所有\(n\)個節點中,有\(f\)個節點可能因故障而沒有回應(或者投票),而在回應的\(n-f\)中又有可能有\(f\)個是惡意節點的回應,即使如此,也要保證正常節點的投票要多於惡意節點的投票數量,即\(n-f-f>f\),推出\(n>3f\)
PBFT對比Raft
PBFT對比Raft,最大的不同在於解決的問題不一樣,雖然都是共識算法,但一個解決的拜占庭問題,另一個則解決的非拜占庭問題。從算法細節上來看,Raft中的領導者是強領導者,即,一切領導者說了算,但PBFT中對應的主節點卻不是,因為不能保證主節點不是拜占庭節點,萬一主節點作惡,從節點要有發現主節點是惡意節點的能力,並及時觸發視圖更換協議更換主節點。從算法消耗的資源來看,明顯PBFT要更複雜,投票數明顯多於Raft,不但要主從節點交互,還有從節點與從節點互相交互,所以,其性能也一定比Raft低,這是肯定的,因為PBFT解決的問題比Raft更複雜,一定程度上可以認為Raft是PBFT的子集,如果你把PBFT三階段協議中從節點與從節點交互的那部分去掉,只保留主節點與從節點交互的那部分,你會發現,好像還蠻像的。從另一個方面說,Raft算法,因為沒有拜占庭節點的存在,領導者節點一定是對的,從節點一切聽領導的就是。但是在PBFT中,從節點就不能光聽主節點的,萬一主節點也是壞人咋辦?怎麼解決這個問題呢?顯然,只聽主節點肯定是不行的,我還要看看其他節點的意見,如果有足額的節點認為是對的,就同意。怎麼確定足額節點數到底是多少呢?上面有講到過。所以,相比Raft,PBFT多了從節點與從節點的消息交互。
PBFT的時間複雜度分析
PBFT有比較明顯的兩輪投票,所以時間複雜度\(O(n^2)\),節點數量較大時,一次共識協商所需的消息太多,這也決定了PBFT只能適用於節點數量不大的系統中,比如區塊鏈中的許可鏈,公鏈節點數量太多,並不適用PBFT算法。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計最專業,超強功能平台可客製化
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※回頭車貨運收費標準
※推薦評價好的iphone維修中心
※教你寫出一流的銷售文案?