目錄
1. 正文
最近在使用GDAL讀寫Shp格式中的屬性字段的時候也遇到了中文亂碼的問題,總結下自己遇到的情況。
1.1. shp文件本身的編碼的問題
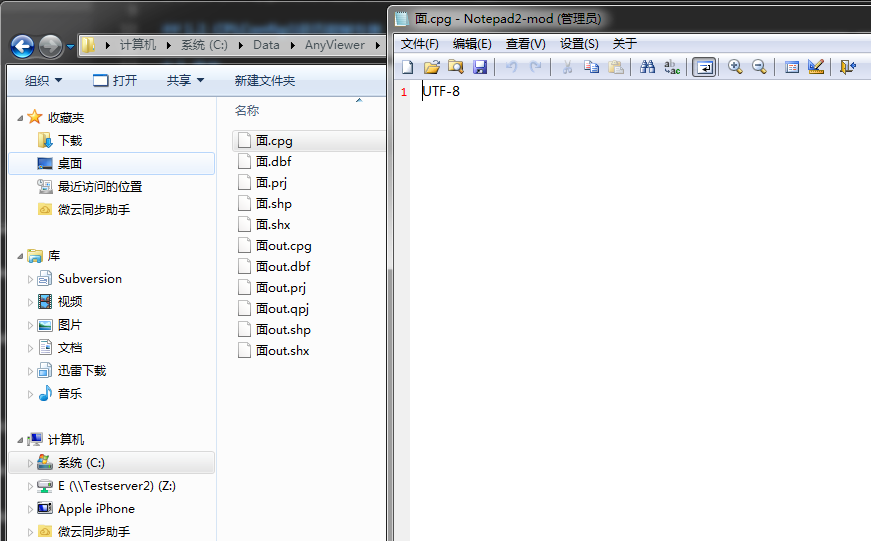
應該是由於shp格式加入了對寬字符的支持,所以導致有段時間的shp文件和ArcGIS是存在不匹配的問題,所以在網上搜索資源的時候遇到了大量的關於ArcMap显示shp屬性表出現亂碼的問題。現在的shp格式的文件應該已經穩定下來了,新添加了一個.cpg的文件,裏面保存着屬性表的編碼格式:
圖1-1:shp格式的.cpg文件
從ArcGIS10.2開始,只要是屬性表編碼與.cpg文件記錄的編碼方式一致,就不會再有显示亂碼的問題。網上查詢到的修改註冊表的方法,我在ArcGIS10.2中試過,似乎已經不再起效了。
那麼對於沒有.cpg或者的情況,應該可以看屬性表.dbf文件。如果編碼方式正確,這個文件用文本編輯器打開是可以看到正常的中文的:
圖1-2:shp格式的.dbf文件
在正常显示中文情況下,可以查看下文件的編碼方式:
圖1-3:查看編碼方式
當然,如果遇到亂碼,可以嘗試用別的編碼方式打開,這樣你就能知道屬性表具體是什麼編碼了。對於國內的情況來說,只有ANSI編碼和UNICODE編碼兩種:其中簡體中文系統中ANSI編碼就是GB2312編碼;UTF-8是UNICODE編碼的一種具體實現。
1.2. 設置讀取的編碼方式
1.2.1. GDAL設置
可以通過全局設置函數CPLSetConfigOption(),來配置讀取Shp文件的讀取編碼。例如對於簡體中文系統中ANSI編碼,可以設置為GBK:
CPLSetConfigOption("SHAPE_ENCODING","GBK");上面這種方式是全局設置的,如果想設置單個文件的編碼方式也是可以的。例如,打開一個矢量文件讀取為UTF-8的數據集:
char** ppszOptions = NULL;
ppszOptions = CSLSetNameValue(ppszOptions, "ENCODING", "UTF-8");
GDALDataset *poDS = (GDALDataset*)GDALOpenEx(filePath.c_str(), GDAL_OF_VECTOR, NULL, ppszOptions, NULL);網上提供的解決方案都是將編碼方式設置為空[1],這種方式應該更具有通用性,起碼我這裏讀取GBK和UTF-8格式的Shp的格式都是可以的:
CPLSetConfigOption("SHAPE_ENCODING","");1.2.2. 解碼方式
如果讀取出來的字段屬性仍然是亂碼,就應該考慮字符串的解碼問題,就是獲取的字段屬性字符串沒有正確的解碼出來。例如讀取UTF-8的Shp文件的屬性字段:
OGRFeature *poFeature;
while ((poFeature = poLayer->GetNextFeature()) != NULL)
{
OGRGeometry *pGeo = poFeature->GetGeometryRef();
OGRwkbGeometryType pGeoType = pGeo->getGeometryType();
//
OGRFeatureDefn *poFDefn = poLayer->GetLayerDefn();
int n = poFDefn->GetFieldCount(); //獲得字段的數目,不包括前兩個字段(FID,Shape);
for (int iField = 0; iField <n; iField++)
{
//輸出每個字段的值
//cout << poFeature->GetFieldAsString(iField) << " ";
cout << UTF8_To_string(poFeature->GetFieldAsString(iField)) << " ";
}
//cout << endl;
OGRFeature::DestroyFeature(poFeature);
}默認情況下,cout是無法正確打印輸出UTF-8字符編碼的,通過UTF8_To_string這個函數,將UTF-8編碼的字符串轉換成本地ANSI編碼,也就是GBK編碼字符串,就可以正確輸出显示了。附帶一下兩者的轉換函數[2]:
// UTF8轉std:string
// 轉換過程:先將utf8轉雙字節Unicode編碼,再通過WideCharToMultiByte將寬字符轉換為多字節。
std::string UTF8_To_string(const std::string& str)
{
int nwLen = MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, NULL, 0);
wchar_t* pwBuf = new wchar_t[nwLen + 1]; //一定要加1,不然會出現尾巴
memset(pwBuf, 0, nwLen * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, str.c_str(), str.length(), pwBuf, nwLen);
int nLen = WideCharToMultiByte(CP_ACP, 0, pwBuf, -1, NULL, NULL, NULL, NULL);
char* pBuf = new char[nLen + 1];
memset(pBuf, 0, nLen + 1);
WideCharToMultiByte(CP_ACP, 0, pwBuf, nwLen, pBuf, nLen, NULL, NULL);
std::string strRet = pBuf;
delete []pBuf;
delete []pwBuf;
pBuf = NULL;
pwBuf = NULL;
return strRet;
}
// std:string轉UTF8
std::string string_To_UTF8(const std::string& str)
{
int nwLen = ::MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, NULL, 0);
wchar_t* pwBuf = new wchar_t[nwLen + 1]; //一定要加1,不然會出現尾巴
ZeroMemory(pwBuf, nwLen * 2 + 2);
::MultiByteToWideChar(CP_ACP, 0, str.c_str(), str.length(), pwBuf, nwLen);
int nLen = ::WideCharToMultiByte(CP_UTF8, 0, pwBuf, -1, NULL, NULL, NULL, NULL);
char* pBuf = new char[nLen + 1];
ZeroMemory(pBuf, nLen + 1);
::WideCharToMultiByte(CP_UTF8, 0, pwBuf, nwLen, pBuf, nLen, NULL, NULL);
std::string strRet(pBuf);
delete []pwBuf;
delete []pBuf;
pwBuf = NULL;
pBuf = NULL;
return strRet;
} 1.2.3. 其他
還有個值得注意的問題就是Shp格式的屬性字段名稱的長度最大隻能支持10個字符。如果採用UTF-8編碼,可能用不了幾个中文字符就被截斷了,這個時候屬性字段名稱也可能存在亂碼。
2. 參考
[1]
[2]
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※大陸寄台灣空運注意事項
※大陸海運台灣交貨時間多久?