※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
透過選單樣式的調整、圖片的縮放比例、文字的放大及段落的排版對應來給使用者最佳的瀏覽體驗,所以不用擔心有手機版網站兩個後台的問題,而視覺效果也是透過我們前端設計師優秀的空間比例設計,不會因為畫面變大變小而影響到整體視覺的美感。
xDeepFM用改良的DCN替代了DeepFM的FM部分來學習組合特徵信息,而FiBiNET則是應用SENET加入了特徵權重比NFM,AFM更進了一步。在看兩個model前建議對DeepFM, Deep&Cross, AFM,NFM都有簡單了解,不熟悉的可以看下文章最後其他model的博客鏈接。
以下代碼針對Dense輸入更容易理解模型結構,針對spare輸入的代碼和完整代碼
https://github.com/DSXiangLi/CTR
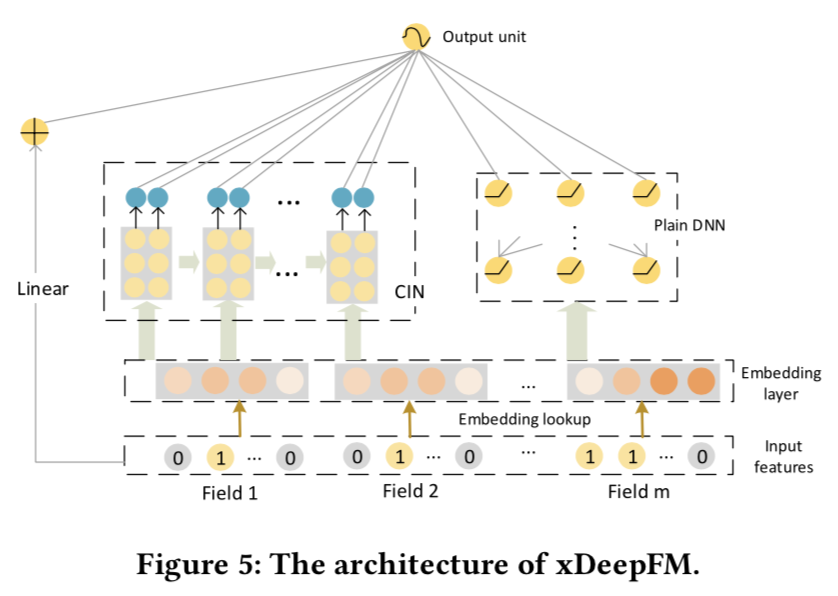
xDeepFM
模型結構
看xDeepFM的名字和DeepFM相似都擁有Deep和Linear的部分,只不過把DeepFM中用來學習二階特徵交互的FM部分替換成了CIN(Compressed Interactino Network)。而CIN是在Deep&Cross的DCN上進一步改良的得到。整體模型結構如下
我們重點看下CIN的部分,和paper的notation保持一致,有m個特徵,每個特徵Embedding是D維,第K層的CIN有\(H_k\)個unit。CIN第K層的計算分為3個部分分別對應圖a-c:
- 向量兩兩做element-wise product, 時間複雜度\(O(m*H_{k-1}*D)\)
對輸入層和第K-1層輸出,做element-wise乘積進行兩兩特徵交互,得到\(m*H_{k-1}\)個D維向量矩陣,如果CIN只有一層,則和FM, NFM,AFM的第一步相同。FM 直接聚合成scaler,NFM沿D進行sum_pooling,而AFM加入Attention沿D進行weighted_pooling。忽略batch的矩陣dimension變化如下
\[z^k = x^0 \odot x^{k-1} = (D * m* 1) \odot (D * 1* H_{k-1}) = D * m*H_{k-1} \]
- Feature Map,空間複雜度\(O(H_k *H_{k-1} *m)\),時間複雜度\(O(H_k *H_{k-1} *m*D)\)
\(W_k \in R^{H_{k-1}*m *H_k}\) 是第K層的權重向量,可以理解為沿Embedding做CNN。每個Filter對所有兩兩乘積的向量進行加權求和得到 \(1*D\)的向量 一共有\(H_k\)個channel,輸出\(H_k * D\)的矩陣向量。
\[w^k \bullet z^k = (H_k *H_{k-1} *m)* (m*H_{k-1}*D) = H_k *D \]
- Sum Pooling
CIN對每層的輸出沿Dimension進行sum pooling,得到\(H_k*1\)的輸出,然後把每層輸出concat以後作為CIN部分的輸出。
CIN每一層的計算如上,T層CIN每一層都是上一次層的輸出和第一層的輸入進行交互得到更高一階的交互信息。假設每層維度一樣\(H_k=H\), CIN 部分整體時間複雜度是\(O(TDmH^2)\),空間複雜度來自每層的Filter權重\(O(TmH^2)\)
CIN保留DCN的任意高階和參數共享,兩個主要差別是
- DCN是bit-wise,CIN是vector-wise。DCN在做向量乘積時不區分Field,直接對所有Field拼接成的輸入(m*D)進行外積。而CIN考慮Field,兩兩vector進行乘積
- DCN使用了ResNet因為多項式的核心只用輸出最後一層,而CIN則是每層都進行pooling后輸出
CIN的設計還是很巧妙滴,不過。。。吐槽小分隊上線: CIN不論是時間複雜度還是空間複雜度都比DCN要高,感覺更容易過擬合。至於說vector-wise的向量乘積要比bit-wise的向量乘積要好,這。。。至少bit-wise可以不限制embedding維度一致, 但vector-wise嘛我實在有些理解無能,明白的童鞋可以comment一下
代碼實現
def cross_op(xk, x0, layer_size_prev, layer_size_curr, layer, emb_size, field_size):
# Hamard product: ( batch * D * HK-1 * 1) * (batch * D * 1* H0) -> batch * D * HK-1 * H0
zk = tf.matmul( tf.expand_dims(tf.transpose(xk, perm = (0, 2, 1)), 3),
tf.expand_dims(tf.transpose(x0, perm = (0, 2, 1)), 2))
zk = tf.reshape(zk, [-1, emb_size, field_size * layer_size_prev]) # batch * D * HK-1 * H0 -> batch * D * (HK-1 * H0)
add_layer_summary('zk_{}'.format(layer), zk)
# Convolution with channel = HK: (batch * D * (HK-1*H0)) * ((HK-1*H0) * HK)-> batch * D * HK
kernel = tf.get_variable(name = 'kernel{}'.format(layer),
shape = (field_size * layer_size_prev, layer_size_curr))
xkk = tf.matmul(zk, kernel)
xkk = tf.transpose(xkk, perm = [0,2,1]) # batch * HK * D
add_layer_summary( 'Xk_{}'.format(layer), xkk )
return xkk
def cin_layer(x0, cin_layer_size, emb_size, field_size):
cin_output_list = []
cin_layer_size.insert(0, field_size) # insert field dimension for input
with tf.variable_scope('Cin_component'):
xk = x0
for layer in range(1, len(cin_layer_size)):
with tf.variable_scope('Cin_layer{}'.format(layer)):
# Do cross
xk = cross_op(xk, x0, cin_layer_size[layer-1], cin_layer_size[layer],
layer, emb_size, field_size ) # batch * HK * D
# sum pooling on dimension axis
cin_output_list.append(tf.reduce_sum(xk, 2)) # batch * HK
return tf.concat(cin_output_list, axis=1)
@tf_estimator_model
def model_fn_dense(features, labels, mode, params):
dense_feature, sparse_feature = build_features()
dense_input = tf.feature_column.input_layer(features, dense_feature)
sparse_input = tf.feature_column.input_layer(features, sparse_feature)
# Linear part
with tf.variable_scope('Linear_component'):
linear_output = tf.layers.dense( sparse_input, units=1 )
add_layer_summary( 'linear_output', linear_output )
# Deep part
dense_output = stack_dense_layer( dense_input, params['hidden_units'],
params['dropout_rate'], params['batch_norm'],
mode, add_summary=True )
# CIN part
emb_size = dense_feature[0].variable_shape.as_list()[-1]
field_size = len(dense_feature)
embedding_matrix = tf.reshape(dense_input, [-1, field_size, emb_size]) # batch * field_size * emb_size
add_layer_summary('embedding_matrix', embedding_matrix)
cin_output = cin_layer(embedding_matrix, params['cin_layer_size'], emb_size, field_size)
with tf.variable_scope('output'):
y = tf.concat([dense_output, cin_output,linear_output], axis=1)
y = tf.layers.dense(y, units= 1)
add_layer_summary( 'output', y )
return y
FiBiNET
模型結構
看FiBiNET前可以先了解下Squeeze-and-Excitation Network,感興趣可以看下這篇博客Squeeze-and-Excitation Networks。
FiBiNET的主要創新是應用SENET學習每個特徵的重要性,加權得到新的Embedding矩陣。在FiBiNET之前,AFM,PNN,DCN和上面的xDeepFM都是在特徵交互之後才用attention, 加權等方式學習特徵交互的權重,而FiBiNET在保留這部分的同時,在Embedding部分就考慮特徵自身的權重。模型結構如下
原始Embedding,和經過SENET調整過權重的新Embedding,在Bilinear-interaction層學習二階交互特徵,拼接后,再經過MLP進一步學習高階特徵。和paper notation保持一致(啊啊啊大家能不能統一下notation搞的我自己看自己的註釋都蒙圈),f個特徵,k維embedding
SENET層
SENET層學習每個特徵的權重對Embedding進行加權,分為以下3步
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
搬家費用:依消費者運送距離、搬運樓層、有無電梯、步行距離、特殊地形、超重物品等計價因素後,評估每車次單
- Squeeze
把\(f*k\)的Embedding矩陣壓縮成\(f*1\), 壓縮方式不固定,SENET原paper用的max_pooling,作者用的sum_pooling,感覺這裏壓縮方式應該取決於Embedding的信息表達
\[\begin{align} E &= [e_1,…,e_f] \\ Z &= [z_1,…,z_f] \\ z_i &= F_{squeeze}(e_i) = \frac{1}{k}\sum_{i=1}^K e_i \\ \end{align} \]
- Excitation
Excitation是一個兩層的全連接層,通過先降維再升維的方式過濾一些無用特徵,降維的幅度通過額外變量\(r\)來控制,第一層權重\(W_1 \in R^{f*f/r}\),第二層權重\(W_2 \in R^{f/r*f}\)。這裏r越高,壓縮的幅度越高,最終的權重會更集中,反之會更分散。
\[A = \sigma_2(W_2·\sigma_1(W_1·Z)) \]
- Re-weight
最後一步就是用Excitation得到的每個特徵的權重對Embedding進行加權得到新Embedding
\[E_{new} = F_{Reweight}(A,E) = [a_1·e_1, …,a_f·e_f ] \]
在收入數據集上進行嘗試,r=2時會有46%的embedding特徵權重為0,所以SENET會在特徵交互前先過濾部分對target無用的特徵來增加有效特徵的權重
Bilinear-Interaction層
作者提出內積和element-wise乘積都不足以捕捉特徵交互信息,因此進一步引入權重W,以下面的方式進行特徵交互
\[v_i · W \odot v_j \]
其中W有三種選擇,可以所有特徵交互共享一個權重矩陣(Field-All),或者每個特徵和其他特徵的交互共享權重(Field-Each), 再或者每個特徵交互一個權重(Field-Interaction) 具體的優劣感覺需要casebycase來試,不過一般還是照着數據越少參數越少的邏輯來整。
原始Embedding和調整權重后的Embedding在Bilinear-Interaction學習交互特徵后,拼接成shallow 層,再經過全連接層來學習更高階的特徵交互。後面的屬於常規操作這裏就不再細說。
我們不去吐槽FiBiNET可以加入wide&deep框架來捕捉低階特徵信息和任意高階信息,更多把FiBiNET提供的SENET特徵權重的思路放到自己的工具箱中就好。
代碼實現
def Bilinear_layer(embedding_matrix, field_size, emb_size, type, name):
# Bilinear_layer: combine inner and element-wise product
interaction_list = []
with tf.variable_scope('BI_interaction_{}'.format(name)):
if type == 'field_all':
weight = tf.get_variable( shape=(emb_size, emb_size), initializer=tf.truncated_normal_initializer(),
name='Bilinear_weight_{}'.format(name) )
for i in range(field_size):
if type == 'field_each':
weight = tf.get_variable( shape=(emb_size, emb_size), initializer=tf.truncated_normal_initializer(),
name='Bilinear_weight_{}_{}'.format(i, name) )
for j in range(i+1, field_size):
if type == 'field_interaction':
weight = tf.get_variable( shape=(emb_size, emb_size), initializer=tf.truncated_normal_initializer(),
name='Bilinear_weight_{}_{}_{}'.format(i,j, name) )
vi = tf.gather(embedding_matrix, indices = i, axis =1, batch_dims =0, name ='v{}'.format(i)) # batch * emb_size
vj = tf.gather(embedding_matrix, indices = j, axis =1, batch_dims =0, name ='v{}'.format(j)) # batch * emb_size
pij = tf.matmul(tf.multiply(vi,vj), weight) # bilinear : vi * wij \odot vj
interaction_list.append(pij)
combination = tf.stack(interaction_list, axis =1 ) # batch * emb_size * (Field_size * (Field_size-1)/2)
combination = tf.reshape(combination, shape = [-1, int(emb_size * (field_size * (field_size-1) /2)) ]) # batch * ~
add_layer_summary( 'bilinear_output', combination )
return combination
def SENET_layer(embedding_matrix, field_size, emb_size, pool_op, ratio):
with tf.variable_scope('SENET_layer'):
# squeeze embedding to scaler for each field
with tf.variable_scope('pooling'):
if pool_op == 'max':
z = tf.reduce_max(embedding_matrix, axis=2) # batch * field_size * emb_size -> batch * field_size
else:
z = tf.reduce_mean(embedding_matrix, axis=2)
add_layer_summary('pooling scaler', z)
# excitation learn the weight of each field from above scaler
with tf.variable_scope('excitation'):
z1 = tf.layers.dense(z, units = field_size//ratio, activation = 'relu')
a = tf.layers.dense(z1, units= field_size, activation = 'relu') # batch * field_size
add_layer_summary('exciitation weight', a )
# re-weight embedding with weight
with tf.variable_scope('reweight'):
senet_embedding = tf.multiply(embedding_matrix, tf.expand_dims(a, axis = -1)) # (batch * field * emb) * ( batch * field * 1)
add_layer_summary('senet_embedding', senet_embedding) # batch * field_size * emb_size
return senet_embedding
@tf_estimator_model
def model_fn_dense(features, labels, mode, params):
dense_feature, sparse_feature = build_features()
dense_input = tf.feature_column.input_layer(features, dense_feature)
sparse_input = tf.feature_column.input_layer(features, sparse_feature)
# Linear part
with tf.variable_scope('Linear_component'):
linear_output = tf.layers.dense( sparse_input, units=1 )
add_layer_summary( 'linear_output', linear_output )
field_size = len(dense_feature)
emb_size = dense_feature[0].variable_shape.as_list()[-1]
embedding_matrix = tf.reshape(dense_input, [-1, field_size, emb_size])
# SENET_layer to get new embedding matrix
senet_embedding_matrix = SENET_layer(embedding_matrix, field_size, emb_size,
pool_op = params['pool_op'], ratio= params['senet_ratio'])
# combination layer & BI_interaction
BI_org = Bilinear_layer(embedding_matrix, field_size, emb_size, type = params['bilinear_type'], name = 'org')
BI_senet = Bilinear_layer(senet_embedding_matrix, field_size, emb_size, type = params['bilinear_type'], name = 'senet')
combination_layer = tf.concat([BI_org, BI_senet] , axis =1)
# Deep part
dense_output = stack_dense_layer(combination_layer, params['hidden_units'],
params['dropout_rate'], params['batch_norm'],
mode, add_summary=True )
with tf.variable_scope('output'):
y = dense_output + linear_output
add_layer_summary( 'output', y )
return y
CTR學習筆記&代碼實現系列
https://github.com/DSXiangLi/CTR
CTR學習筆記&代碼實現1-深度學習的前奏 LR->FFM
CTR學習筆記&代碼實現2-深度ctr模型 MLP->Wide&Deep
CTR學習筆記&代碼實現3-深度ctr模型 FNN->PNN->DeepFM
CTR學習筆記&代碼實現4-深度ctr模型 NFM/AFM
CTR學習筆記&代碼實現5-深度ctr模型 DeepCrossing -> Deep&Cross
Ref
- Jianxun Lian, 2018, xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
- Tongwen Huang, 2019, FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
- Jie Hu, 2017, Squeeze-and-Excitation Networks
- https://zhuanlan.zhihu.com/p/72931811
- https://zhuanlan.zhihu.com/p/79659557
- https://zhuanlan.zhihu.com/p/57162373
- https://github.com/qiaoguan/deep-ctr-prediction
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
節能減碳愛地球是景泰電動車的理念,是創立景泰電動車行的初衷,滿意態度更是服務客戶的最高品質,我們的成長來自於你的推薦。