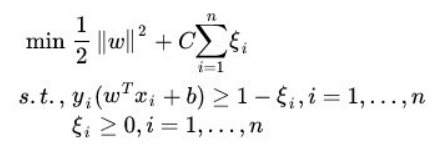上一節我學習了SVM的推導過程,下面學習如何實現SVM,具體的參考鏈接都在第一篇文章中,SVM四篇筆記鏈接為:
Python機器學習筆記:SVM(1)——SVM概述
Python機器學習筆記:SVM(2)——SVM核函數
Python機器學習筆記:SVM(3)——證明SVM
Python機器學習筆記:SVM(4)——sklearn實現
對SVM的概念理清楚后,下面我們對其使用sklearn進行實現。
1,Sklearn支持向量機庫概述
我們知道SVM相對感知器而言,它可以解決線性不可分的問題,那麼它是如何解決的呢?其思想很簡單就是對原始數據的維度變換,一般是擴維變換,使得原樣本空間中的樣本點線性不可分,但是在變維之後的空間中樣本點是線性可分的,然後再變換后的高維空間中進行分類。
上面將SVM再贅述了一下,下面學習sklearn中的SVM方法,sklearn中SVM的算法庫分為兩類,一類是分類的算法庫,主要包含LinearSVC,NuSVC和SVC三個類,另一類是回歸算法庫,包含SVR,NuSVR和LinearSVR三個類,相關模塊都包裹在sklearn.svm模塊中。
對於SVC,NuSVC和LinearSVC 三個分類的庫,SVC和NuSVC差不多,區別僅僅在於對損失的度量方式不同,而LinearSVC從名字就可以看出,他是線性分類,也就是不支持各種低維到高維的核函數,僅僅支持線性核函數,對線性不可分的數據不能使用。
同樣的對於SVR,NuSVR和LinearSVR 三個回歸的類,SVR和NuSVR差不多,區別也僅僅在於對損失的度量方式不同。LinearSVR是線性回歸,只能使用線性核函數。
我們使用這些類的時候,如果有經驗知道數據是線性可以擬合的,那麼使用LinearSVC去分類或者LinearSVR去回歸,他們不需要我們去慢慢的調參選擇各種核函數以及對應的參數,速度也快。如果我們對數據分佈沒有什麼經驗,一般使用SVC去分類或者SVR去回歸,這就需要我們選擇核函數以及對核函數調參了。
2,回顧SVM分類算法和回歸算法
我們這裏仍然先對SVM算法進行回顧,首先對於SVM分類算法,其原始形式如下:
其中 n 為樣本個數,我們的樣本為(x1, y1),(x2,y2),….(xn, yn),w,b是我們的分離超平面的 wT*xi + b = 0的係數,ξi 為第 i 個樣本的鬆弛係數,C 為懲罰係數,xi (也有時候寫為Φ(xi) 為低維到高維的映射函數)為樣本數。
通過拉格朗日以及對偶化后的形式為:
其中和原始形式不同的 α 為拉格朗日係數向量,<xi, xj> 為我們要使用的核函數。
對於SVM回歸算法,(我自己沒有總結,借用劉建平老師的博客),其原始形式如下:
其中 m 為樣本個數,我們的樣本為(x1, y1),(x2, y2),….,(xm, ym),w,b是我們回歸超平面 wT*xi + b = 0 的係數,ξv, ξ^ 為第 i 個樣本的鬆弛係數, C為懲罰係數,ε 為損失邊界,到超平面距離小於 ε 的訓練集的點沒有損失,Φ(xi) 為低維到高維的映射函數
通過拉格朗日函數以及對偶后的形式為:
其中和原始形式不同的 αv, α^ 為拉格朗日係數向量,K(xi, xj) 為我們要使用的核函數。
3,SVM核函數概述
我在第二篇SVM中學習了核函數,有好幾種,最常用的就是線性核函數,多項式核函數,高斯核函數和Sigmoid核函數,在scikit-learn中,內置的核函數也剛好有這四種。
3.1,線性核函數(Linear Kernel)
線性核函數表達式為:
就是普通的內積,LinearSVC和LinearSVR只能使用它。
3.2,多項式核函數(Polynomial Kernel)
多項式核函數是線性不可分SVM常用的核函數之一,表達式為:
參數都需要自己調參定義,比較麻煩。
3.3,高斯核函數(Gaussian Kernel)
高斯核函數,在SVM中也稱為 徑向基核函數(Radial Basisi Function,RBF),它是libsvm默認的核函數,當然也是sklearn默認的核函數,表達式為:
其中 r 大於0,需要自己調參定義,不過一般情況,我們都使用高斯核函數。
3.4,Sigmoid核函數(Sigmoid Kernel)
Sigmoid核函數也是線性不可分SVM常用的核函數之一,表示為:
其中 beta, t 都需要自己調參定義。
一般情況下,對於非線性數據使用默認的高斯核函數會有比較好的效果,如果你不是SVM調參高手的話,建議使用高斯核來做數據分析。
4,SVM分類算法庫參數小結
下面我們將具體介紹這三種分類方法都有那些參數值以及不同參數值的含義。
4.1, LinearSVC
其函數原型如下:
class sklearn.svm.LinearSVC(self, penalty='l2', loss='squared_hinge', dual=True, tol=1e-4,
C=1.0, multi_class='ovr', fit_intercept=True,
intercept_scaling=1, class_weight=None, verbose=0,
random_state=None, max_iter=1000)
參數說明
- penalty :正則化參數,L1 和L2兩種參數可選,僅LinearSVC有。默認是L2 正則化,如果我們需要產生稀疏的話,可以選擇L1正則化,這和線性回歸裏面的Lasso回歸類似
- loss:損失函數,有“hinge” 和“squared_hinge” 兩種可選,前者又稱為L1損失,後者稱為L2損失,默認是“squared_hinge”,其中hinge是SVM的標準損失,squared_hinge是hinge的平方。
- dual:是否轉化為對偶問題求解,默認是True。這是一個布爾變量,控制是否使用對偶形式來優化算法。
- tol:殘差收斂條件,默認是0.0001,與LR中的一致。
- C:懲罰係數,用來控制損失函數的懲罰係數,類似於LR中的正則化係數。默認為1,一般需要通過交叉驗證來選擇一個合適的C,一般來說,噪點比較多的時候,C需要小一些。
- multi_class:負責多分類問題中分類策略制定,有‘ovr’和‘crammer_singer’ 兩種參數值可選,默認值是’ovr’,’ovr’的分類原則是將待分類中的某一類當作正類,其他全部歸為負類,通過這樣求取得到每個類別作為正類時的正確率,取正確率最高的那個類別為正類;‘crammer_singer’ 是直接針對目標函數設置多個參數值,最後進行優化,得到不同類別的參數值大小。
- fit_intercept:是否計算截距,與LR模型中的意思一致。
- class_weight:與其他模型中參數含義一樣,也是用來處理不平衡樣本數據的,可以直接以字典的形式指定不同類別的權重,也可以使用balanced參數值。如果使用“balanced”,則算法會自己計算權重,樣本量少的類別所對應的樣本權重會高,當然,如果你的樣本類別分佈沒有明顯的偏倚,則可以不管這個係數,選擇默認的None
- verbose:是否冗餘,默認為False
- random_state:隨機種子的大小
- max_iter:最大迭代次數,默認為1000.
懲罰係數:
錯誤項的懲罰係數。C越大,即對分錯樣本的懲罰程度越大,因此在訓練樣本中準確率越高,但是泛化能力降低,也就是對測試數據的分類準確率降低。相反,減少C的話,容許訓練樣本中有一些誤分類錯誤樣本,泛化能力強。對於訓練樣本帶有噪音的情況,一般採用後者,把訓練樣本集中錯誤分類的樣本作為噪音。
4.2,NuSVC
其函數原型如下:
class sklearn.svm.NuSVC(self, nu=0.5, kernel='rbf', degree=3, gamma='auto_deprecated',
coef0=0.0, shrinking=True, probability=False, tol=1e-3,
cache_size=200, class_weight=None, verbose=False, max_iter=-1,
decision_function_shape='ovr', random_state=None)
參數說明:
- nu:訓練誤差部分的上限和支持向量部分的下限,取值在(0,1)之間,默認是0.5,它和懲罰係數C類似,都可以控制懲罰的力度。
- kernel:核函數,核函數是用來將非線性問題轉化為線性問題的一種方法,默認是“rbf”核函數
常用的核函數有以下幾種:
- degree:當核函數是多項式核函數(“poly”)的時候,用來控制函數的最高次數。(多項式核函數是將低維的輸入空間映射到高維的特徵空間),這個參數只對多項式核函數有用,是指多項式核函數的階數 n。如果給的核函數參數是其他核函數,則會自動忽略該參數。
- gamma:核函數係數,默認是“auto”,即特徵維度的倒數。核函數係數,只對rbf poly sigmoid 有效。
- coef0:核函數常數值( y = kx + b 的b值),只有“poly”和“sigmoid” 函數有,默認值是0.
- max_iter:最大迭代次數,默認值是 -1 ,即沒有限制。
- probability:是否使用概率估計,默認是False。
- decision_function_shape:與“multi_class”參數含義類似,可以選擇“ovo” 或者“ovr”(0.18版本默認是“ovo”,0.19版本為“ovr”) OvR(one vs rest)的思想很簡單,無論你是多少元分類,我們都可以看做二元分類,具體的做法是,對於第K類的分類決策,我們把所有第K類的樣本作為正例,除第K類樣本以外的所有樣本作為負類,然後在上面做二元分類,得到第K類的分類模型。 OvO(one vs one)則是每次在所有的T類樣本裏面選擇兩類樣本出來,不妨記為T1類和T2類,把所有的輸出為T1 和 T2的樣本放在一起,把T1作為正例,T2 作為負例,進行二元分類,得到模型參數,我們一共需要T(T-1)/2 次分類。從上面描述可以看出,OvR相對簡單,但是分類效果略差(這裡是指大多數樣本分佈情況,某些樣本分佈下OvR可能更好),而OvO分類相對精確,但是分類速度沒有OvR快,一般建議使用OvO以達到較好的分類效果
- chache_size:緩衝大小,用來限制計算量大小,默認是200M,如果機器內存大,推薦使用500MB甚至1000MB
4.3,SVC
其函數原型如下:
class sklearn.svm.SVC(self, C=1.0, kernel='rbf', degree=3, gamma='auto_deprecated',
coef0=0.0, shrinking=True, probability=False,
tol=1e-3, cache_size=200, class_weight=None,
verbose=False, max_iter=-1, decision_function_shape='ovr',
random_state=None)
參數說明:
SVC和NuSVC方法基本一致,唯一區別就是損失函數的度量方式不同(NuSVC中的nu參數和SVC中的C參數)即SVC使用懲罰係數C來控制懲罰力度,而NuSVC使用nu來控制懲罰力度。
5,SVM回歸算法庫參數小結
下面我們將具體介紹這三種分類方法都有那些參數值以及不同參數值的含義。
5.1, LinearSVR
其函數原型如下:
class sklearn.svm.LinearSVR(self, epsilon=0.0, tol=1e-4, C=1.0,
loss='epsilon_insensitive', fit_intercept=True,
intercept_scaling=1., dual=True, verbose=0,
random_state=None, max_iter=1000)
參數說明
- epsilon:距離誤差epsilon,即回歸模型中的 epsilon,訓練集中的樣本需要滿足:
- loss:損失函數,有“hinge” 和“squared_hinge” 兩種可選,前者又稱為L1損失,後者稱為L2損失,默認是“squared_hinge”,其中hinge是SVM的標準損失,squared_hinge是hinge的平方。
- dual:是否轉化為對偶問題求解,默認是True。這是一個布爾變量,控制是否使用對偶形式來優化算法。
- tol:殘差收斂條件,默認是0.0001,與LR中的一致。
- C:懲罰係數,用來控制損失函數的懲罰係數,類似於LR中的正則化係數。默認為1,一般需要通過交叉驗證來選擇一個合適的C,一般來說,噪點比較多的時候,C需要小一些。
- fit_intercept:是否計算截距,與LR模型中的意思一致。
- verbose:是否冗餘,默認為False
- random_state:隨機種子的大小
- max_iter:最大迭代次數,默認為1000.
5.2,NuSVR
其函數原型如下:
class sklearn.svm.NuSVR(self, nu=0.5, C=1.0, kernel='rbf', degree=3,
gamma='auto_deprecated', coef0=0.0, shrinking=True,
tol=1e-3, cache_size=200, verbose=False, max_iter=-1)
參數說明:
- nu:訓練誤差部分的上限和支持向量部分的下限,取值在(0,1)之間,默認是0.5,它和懲罰係數C類似,都可以控制懲罰的力度。
- kernel:核函數,核函數是用來將非線性問題轉化為線性問題的一種方法,默認是“rbf”核函數
常用的核函數有以下幾種:
- degree:當核函數是多項式核函數(“poly”)的時候,用來控制函數的最高次數。(多項式核函數是將低維的輸入空間映射到高維的特徵空間),這個參數只對多項式核函數有用,是指多項式核函數的階數 n。如果給的核函數參數是其他核函數,則會自動忽略該參數。
- gamma:核函數係數,默認是“auto”,即特徵維度的倒數。核函數係數,只對rbf poly sigmoid 有效。
- coef0:核函數常數值( y = kx + b 的b值),只有“poly”和“sigmoid” 函數有,默認值是0.
- chache_size:緩衝大小,用來限制計算量大小,默認是200M,如果機器內存大,推薦使用500MB甚至1000MB
5.3,SVR
其函數原型如下:
class sklearn.svm.SVC(self, kernel='rbf', degree=3, gamma='auto_deprecated',
coef0=0.0, tol=1e-3, C=1.0, epsilon=0.1, shrinking=True,
cache_size=200, verbose=False, max_iter=-1)
參數說明:
SVR和NuSVR方法基本一致,唯一區別就是損失函數的度量方式不同(NuSVR中的nu參數和SVR中的C參數)即SVR使用懲罰係數C來控制懲罰力度,而NuSVR使用nu來控制懲罰力度。
6,SVM的方法與對象
6.1 方法
三種分類的方法基本一致,所以一起來說:
- decision_function(x):獲取數據集X到分離超平面的距離
- fit(x , y):在數據集(X,y)上使用SVM模型
- get_params([deep]):獲取模型的參數
- predict(X):預測數值型X的標籤
- score(X,y):返回給定測試集合對應標籤的平均準確率
6.2 對象
- support_:以數組的形式返回支持向量的索引
- support_vectors_:返回支持向量
- n_support_:每個類別支持向量的個數
- dual_coef:支持向量係數
- coef_:每個特徵係數(重要性),只有核函數是LinearSVC的是可用,叫權重參數,即w
- intercept_:截距值(常數值),稱為偏置參數,即b
加粗的三個屬性是我們常用的,後面會舉例說明 support_vectors_。
7,SVM類型算法的模型選擇
7.1 PPT總結
這裏使用(http://staff.ustc.edu.cn/~ketang/PPT/PRLec5.pdf)的PPT進行整理。
7.2 SVM算法庫其他調參要點
下面再對其他調參要點做一個小結:
- 1,一般推薦在做訓練之前對數據進行歸一化,當然測試集的數據也要做歸一化
- 2,在特徵數非常多的情況下,或者樣本數遠小於特徵數的時候,使用線性核,效果就很好了,並且只需要選擇懲罰係數C即可
- 3,在選擇核函數的時候,如果線性擬合效果不好,一般推薦使用默認的高斯核(rbf),這時候我們主要對懲罰係數C和核函數參數 gamma 進行調參,經過多輪的交叉驗證選擇合適的懲罰係數C和核函數參數gamma。
- 4,理論上高斯核不會比線性核差,但是這個理論就建立在要花費更多的時間上調參上,所以實際上能用線性核解決的問題我們盡量使用線性核函數
在SVM中,其中最重要的就是核函數的選取和參數選擇了,當然這個需要大量的經驗來支撐,這裏幾個例子只是自己網上找的SVM的小例子。
8,SVM調參實例1
下面學習支持向量機的使用方法以及一些參數的調整,支持向量機的原理就是將低維不可分問題轉換為高維可分問題。這裏不再贅述。
8.1 線性可分支持向量機
首先做一個簡單的線性可分的例子,這裏直接使用sklearn.datasets.make_blobs 生成數據。生成數據代碼如下:
# 生成數據集
from sklearn.datasets.samples_generator import make_blobs
from matplotlib import pyplot as plt
# n_samples=50 表示取50個點,centers=2表示將數據分為兩類
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.6)
# 畫圖形
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plt.show()
我們畫圖展示如下:
我們嘗試繪製分離兩組數據的直線,從而創建分類模型,對於這裏所示的數據,這是我們可以手動完成的任務。但是立馬可以看出有很多分界線可以完美的區分兩個類。
下面畫出決策邊界。
# 生成數據集
from sklearn.datasets.samples_generator import make_blobs
from matplotlib import pyplot as plt
import numpy as np
# n_samples=50 表示取50個點,centers=2表示將數據分為兩類
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.6)
# 畫圖形
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
# 線性等分詳細
xfit = np.linspace(-1, 3.5)
plt.plot([0.6], [2.1], 'x', color='red', markeredgewidth=2, markersize=10)
for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]:
plt.plot(xfit, m * xfit + b, '-k')
plt.show()
圖如下:
(注意:這三條直線是我隨便畫的,其實你可以使用Logistic回歸,線性回歸等分類,畫出線,我這裡是為了方便)
這裡是三條不同的分割直線,並且這些分割直線能夠完全區分這些樣例。但是根據支持向量機的思想,哪一條直線是最優的分割線呢?支持向量機並不是簡單的繪製一條直線,而是畫出邊距為一定寬度的直線,直到最近的點。
下面我們對直線進行加粗,代碼如下:
# 生成數據集
from sklearn.datasets.samples_generator import make_blobs
from matplotlib import pyplot as plt
import numpy as np
# n_samples=50 表示取50個點,centers=2表示將數據分為兩類
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.6)
# 畫圖形
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
# 線性等分詳細
xfit = np.linspace(-1, 3.5)
plt.plot([0.6], [2.1], 'x', color='red', markeredgewidth=2, markersize=10)
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, '-k')
plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none',
color='#AAAAAA', alpha=0.4) # alpha為透明度
plt.show()
如圖所示:
在支持向量機中,邊距最大化的直線是我們將選擇的最優模型。支持向量機是這種最大邊距估計器的一個例子。
接下來,我們訓練一個基本的SVM,我們使用sklearn的支持向量機,對這些數據訓練SVM模型。目前我們將使用一個線性核並將C參數設置為一個默認的數值。如下:
from sklearn.svm import SVC # Support Vector Classifier
model = SVC(kernel='linear') # 線性核函數
model.fit(X, y)
我們順便看看SVC的所有參數情況:
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='linear', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
為了更好展現這裏發生的事情,下面我們創建一個輔助函數,為我們繪製SVM的決策邊界。
def plot_SVC_decision_function(model, ax=None, plot_support=True):
'''Plot the decision function for a 2D SVC'''
if ax is None:
ax = plt.gca() #get子圖
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# create grid to evaluate model
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
# 生成網格點和坐標矩陣
Y, X = np.meshgrid(y, x)
# 堆疊數組
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
# plot decision boundary and margins
ax.contour(X, Y, P, colors='k', levels=[-1, 0, 1],
alpha=0.5, linestyles=['--', '-', '--']) # 生成等高線 --
# plot support vectors
if plot_support:
ax.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, linewidth=1, facecolors='none')
ax.set_xlim(xlim)
ax.set_ylim(ylim)
下面繪製決策邊界:
def train_SVM():
# n_samples=50 表示取50個點,centers=2表示將數據分為兩類
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.6)
# 線性核函數
model = SVC(kernel='linear')
model.fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_SVC_decision_function(model)
plt.show()
return X, y
結果如圖所示:
這是最大化兩組點之間的間距的分界線,那中間這條線就是我們最終的決策邊界了。請注意:一些訓練點碰到了邊緣,如圖所示,在兩個邊界上包含兩個紅點和一個黃點,所以這三個點又稱為支持向量,是 alpha 值不為零的,這些點是這種擬合的關鍵要素,被稱為支持向量。在sklearn中,這些點存儲在分類器的 support_vectors_ 屬性中。
我們通過下面代碼可以得出支持向量的結果。
print(model.support_vectors_)
'''
[[0.44359863 3.11530945]
[2.33812285 3.43116792]
[2.06156753 1.96918596]]
'''
在支持向量機只有位於支持向量上面的點才會對決策邊界有影響,也就是說不管有多少的點是非支持向量,那對最終的決策邊界都不會產生任何影響。我們可以看到這一點,例如,如果我們繪製該數據集的前 60個點和前120個點獲得的模型:
def plot_svm(N=10, ax=None):
X, y = make_blobs(n_samples=200, centers=2, random_state=0, cluster_std=0.6)
X, y = X[:N], y[:N]
model = SVC(kernel='linear')
model.fit(X, y)
ax = ax or plt.gca()
ax.scatter(X[:, 0], X[:, 1], c=y, cmap='autumn')
ax.set_xlim(-1, 4)
ax.set_ylim(-1, 6)
plot_SVC_decision_function(model, ax)
if __name__ == '__main__':
# train_SVM()
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, N in zip(ax, [60, 120]):
plot_svm(N, axi)
axi.set_title('N = {0}'.format(N))
結果如圖所示:
上面就是我們繪製的該數據集前60個點和前120個點獲得的模型,可以發現無論使用60,還是使用120個數據點,決策邊界都沒有發生變換,所有隻要支持向量沒變,其他的數據怎麼加都無所謂。
這個分類器成功的關鍵在於:為了擬合,只有支持向量的位置是最重要的;任何遠離邊距的點都不會影響擬合的結果,邊界之外的點無論有多少都不會對其造成影響,也就是說不管有多少點是非支持向量,對最終的決策邊界都不會產生任何影響。
8.2 線性不可分支持向量機
下面引入核函數,來看看核函數的威力,首先我們導入一個線性不可分的數據集。
def train_svm_plus():
# 二維圓形數據 factor 內外圓比例(0, 1)
X, y = make_circles(100, factor=0.1, noise=0.1)
clf = SVC(kernel='linear')
clf.fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_SVC_decision_function(clf, plot_support=False)
數據集如圖所示:
很明顯,用線性分類器無論怎麼畫線也不能分好,那咋辦呢?下面試試高斯核變換吧。在進行核變換之前,先看看數據在高維空間下的映射:
def plot_3D(X, y, elev=30, azim=30):
# 我們加入了新的維度 r
r = np.exp(-(X ** 2).sum(1))
ax = plt.subplot(projection='3d')
ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap='autumn')
ax.view_init(elev=elev, azim=azim)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
if __name__ == '__main__':
X, y = train_svm_plus()
plot_3D(elev=30, azim=30, X=X, y=y)
畫出三維圖形,如圖所示:
見證核變換威力的時候到了,引入徑向基函數(也叫高斯核函數),進行核變換:
def train_svm_plus():
# 二維圓形數據 factor 內外圓比例(0, 1)
X, y = make_circles(100, factor=0.1, noise=0.1)
# 加入徑向基函數
clf = SVC(kernel='rbf')
clf.fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_SVC_decision_function(clf, plot_support=False)
return X, y
得到的SVM模型為:
SVC(C=1000000.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='rbf', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
再次進行分類任務,代碼如下:
def train_svm_plus():
# 二維圓形數據 factor 內外圓比例(0, 1)
X, y = make_circles(100, factor=0.1, noise=0.1)
# 加入徑向基函數
clf = SVC(kernel='rbf')
clf.fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_SVC_decision_function(clf, plot_support=False)
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=300, lw=1, facecolors='none')
return X, y
分類結果如圖所示:
可以清楚的看到效果很好,我們將線性不可分的兩對數據分割開來。使用這種核支持向量機,我們學習一個合適的非線性決策邊界。這種核變換策略在機器學習中經常被使用。
8.3 線性近似可分支持向量機——軟間隔問題
SVM模型有兩個非常重要的參數C與gamma,其中C是懲罰係數,即對誤差的寬容忍,C越高,說明越不能容忍出現誤差,容易過擬合。C越小,容易欠擬合。C過大或過小,泛化能力變差。
gamma 是選擇 RBF 函數作為kernel后,該函數自帶的一個參數。隱含的決定了數據映射到新的特徵空間后的分佈,gamma越大,支持向量越小,gamma值越小,支持向量越多。
下面我們分別調劑一下C和gamma來看一下對結果的影響。
首先我們調節C,先做一個有噪音的數據分佈
# n_samples=50 表示取50個點,centers=2表示將數據分為兩類
X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
結果如圖所示:
上面的分佈看起來要劃分似乎有點困難,所以我們可以進行軟件各調整看看。
# n_samples=50 表示取50個點,centers=2表示將數據分為兩類
X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.8)
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, C in zip(ax, [10.0, 0.1]):
model = SVC(kernel='linear', C=C)
model.fit(X, y)
axi.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_SVC_decision_function(model, axi)
axi.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, lw=1, facecolors='none')
axi.set_title('C={0:.1f}'.format(C), size=14)
結果如圖所示:
可以看到左邊這幅圖C值比較大,要求比較嚴格,不能分錯東西,隔離帶中沒有進入任何一個點,但是隔離帶的距離比較小,泛化能力比較差。右邊這幅圖C值比較小,要求相對來說比較松一點,隔離帶較大,但是隔離帶中進入了很多的黃點和紅點。那麼C大一些好還是小一些好呢?這需要考慮實際問題,可以進行K折交叉驗證來得到最合適的C值。
下面再看看另一個參數gamma值,這個參數值只是在高斯核函數裏面才有,這個參數控制着模型的複雜程度,這個值越大,模型越複雜,值越小,模型就越精簡。
代碼如下:
# n_samples=50 表示取50個點,centers=2表示將數據分為兩類
X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.8)
fig, ax = plt.subplots(1, 3, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, gamma in zip(ax, [10.0, 1.0, 0.1]):
model = SVC(kernel='rbf', gamma=gamma)
model.fit(X, y)
axi.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')
plot_SVC_decision_function(model, axi)
axi.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, lw=1, facecolors='none')
axi.set_title('gamma={0:.1f}'.format(gamma), size=14)
結果如下:
可以看出,當這個參數較大時,可以看出模型分類效果很好,但是泛化能力不太好。當這個參數較小時,可以看出模型裏面有些分類是錯誤的,但是這個泛化能力更好,一般也應有的更多。
通過這個簡單的例子,我們對支持向量機在SVM中的基本使用,以及軟間隔參數的調整,還有核函數變換和gamma值等一些參數的比較。
完整代碼請參考我的GitHub(地址:https://github.com/LeBron-Jian/MachineLearningNote)。
9,SVM調參實例2
下面我們用一個實例學習SVM RBF分類調參(此例子是劉建平老師的博客內容,鏈接在文後)。
首先,我們生成一些隨機數據,為了讓數據難一點,我們加入了一些噪音,代碼如下:
# _*_coding:utf-8_*_
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_moons, make_circles
from sklearn.preprocessing import StandardScaler
from matplotlib.colors import ListedColormap
X, y = make_circles(noise=0.2, factor=0.5, random_state=1)
# 對數據進行標準化
X = StandardScaler().fit_transform(X)
# 下面看看數據長什麼樣子
cm = plt.cm.RdBu
cm_birght = ListedColormap(['#FF0000', '#0000FF'])
ax = plt.subplot()
ax.set_title('Input data')
# plot the training points
ax.scatter(X[:, 0], X[:, 1], c=y, cmap=cm_birght)
ax.set_xticks([])
ax.set_yticks([])
plt.tight_layout()
plt.show()
上面代碼對數據做了標準化,注意做標準化和不做標準化的差異(不一定所有的數據標準化后的效果更好,但是絕大多數確實更好)。比如下圖:
我們看,當不做數據標準化,我們x1的取值範圍由0~90不等,當做了數據標準化之後,其取值範圍就在-2~2之間了。說明標準化的作用還是很明顯的,不多贅述,下面繼續。
生成的數據如下(可能下一次運行,就變了哈):
知道數據長什麼樣了,下面我們要對這個數據集進行SVM RBF分類了,分類時我們採用了網格搜索,在C=(0.1, 1, 10)和 gamma=(1, 0.1, 0.01)形成的9種情況中選擇最好的超參數,我們用了4折交叉驗證。這裏只是一個例子,實際運用中,可能需要更多的參數組合來進行調參。
代碼及其結果如下:
# 網格搜索尋找最佳參數
grid = GridSearchCV(SVC(), param_grid={'C': [0.1, 1, 10], 'gamma': [1, 0.1, 0.01]}, cv=4)
grid.fit(X, y)
print("The best parameters are %s with a score of %0.2f"
% (grid.best_params_, grid.best_score_))
# The best parameters are {'C': 10, 'gamma': 0.1} with a score of 0.91
就是說,我們通過網格搜索,在我們給定的9組超參數組合中,C=10, gamma=0.1 分數最高,這就是我們最終的參數候選。
下面我們看看SVM分類后的可視化,這裏我們把上面九種組合各個訓練后,通過對網格里的點預測來標色,觀察分類的效果圖,代碼如下:
# SVM 分類後進行可視化
x_min, x_max = X[:, 0].min(), X[:, 0].max() + 1
y_min, y_max = X[:, 1].min(), X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
for i, C in enumerate((0.1, 1, 10)):
for j, gamma in enumerate((1, 0.1, 0.01)):
# plt.subplot()
clf = SVC(C=C, gamma=gamma)
clf.fit(X, y)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# put the result into a color plot
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.xlabel(" gamma=" + str(gamma) + " C=" + str(C))
plt.show()
結果如下:
從我測試的結果來看,劉老師的代碼還是有一點點問題,显示不出九個,所以這裏我打算重新學習一個例子。
完整代碼請參考我的GitHub(地址:https://github.com/LeBron-Jian/MachineLearningNote)。
10,SVM調參實例3(非線性支持向量機)
非線性的話,我們一方面可以利用核函數構造出非線性,一方面我們可以自己構造非線性。下面首先學習自己構造非線性。
10.1 自己構造非線性數據
我們構造非線性數據的代碼如下:
# _*_coding:utf-8_*_
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_moons, make_circles
from sklearn.preprocessing import StandardScaler
X1D = np.linspace(-4, 4, 9).reshape(-1, 1)
# np.c_是按行連接兩個矩陣,就是把兩矩陣左右相加,要求行數相等。
X2D = np.c_[X1D, X1D ** 2]
y = np.array([0, 0, 1, 1, 1, 1, 1, 0, 0])
plt.figure(figsize=(11, 4))
plt.subplot(121)
plt.grid(True, which='both')
plt.axhline(y=0, color='k')
plt.plot(X1D[:, 0][y == 0], np.zeros(4), 'bs')
plt.plot(X1D[:, 0][y == 1], np.zeros(5), 'g*')
plt.gca().get_yaxis().set_ticks([])
plt.xlabel(r'$x_1$', fontsize=20)
plt.axis([-4.5, 4.5, -0.2, 0.2])
plt.subplot(122)
plt.grid(True, which='both')
plt.axhline(y=0, color='k')
plt.axvline(x=0, color='k')
plt.plot(X2D[:, 0][y == 0], X2D[:, 1][y == 0], 'bs')
plt.plot(X2D[:, 0][y == 1], X2D[:, 1][y == 1], 'g*')
plt.xlabel(r'$x_1$', fontsize=20)
plt.ylabel(r'$x_2$', fontsize=20, rotation=0)
plt.gca().get_yaxis().set_ticks([0, 4, 8, 12, 16])
plt.plot([-4.5, 4.5], [6.5, 6.5], 'r--', linewidth=3)
plt.axis([-4.5, 4.5, -1, 17])
plt.subplots_adjust(right=1)
plt.show()
圖如下:
從這個圖可以看到,我們利用對數據的變換,可以對數據的維度增加起來,變成非線性。
假設我們不使用核函數的思想,先對數據做變換,看能不能達到一個比較好的結果,首先我們做一個測試的數據,代碼如下:
# _*_coding:utf-8_*_
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
def plot_dataset(X, y, axes):
plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], 'bs')
plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], 'g*')
plt.axis(axes)
plt.grid(True, which='both')
plt.xlabel(r'$x_1$', fontsize=20)
plt.ylabel(r'$x_2$', fontsize=20, rotation=0)
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.show()
生成的圖如下:
下面代碼將兩類數據分出來了:
Polynomial_svm_clf = Pipeline((('poly_features', PolynomialFeatures(degree=3)),
('scaler', StandardScaler()),
('svm_clf', LinearSVC(C=10))
))
Polynomial_svm_clf.fit(X, y)
def plot_predictions(clf, axes):
x0s = np.linspace(axes[0], axes[1], 100)
x1s = np.linspace(axes[2], axes[3], 100)
x0, x1 = np.meshgrid(x0s, x1s)
X = np.c_[x0.ravel(), x1.ravel()]
y_pred = clf.predict(X).reshape(x0.shape)
# 下面填充一個等高線, alpha表示透明度
plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2)
plot_predictions(Polynomial_svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.show()
結果如下:
從結果來看,我們使用線性支持向量機將兩類數據區分開是沒有問題的。而最重要的是我們如何使用核函數呢?下面繼續學習
10.2 如何對非線性數據進行核函數的變換
我們首先看svm的官方文檔:
核函數默認是 rbf,也就是徑向基核函數。下面分別演示核函數。
我們依舊拿上面的數據,首先取核函數為 多項式核 看看效果(這裏對比的是多項式核的degree,也就是多項式核的維度):
# _*_coding:utf-8_*_
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC, SVC
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
def plot_dataset(X, y, axes):
plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], 'bs')
plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], 'g*')
plt.axis(axes)
plt.grid(True, which='both')
plt.xlabel(r'$x_1$', fontsize=20)
plt.ylabel(r'$x_2$', fontsize=20, rotation=0)
# 展示圖像
def plot_predictions(clf, axes):
x0s = np.linspace(axes[0], axes[1], 100)
x1s = np.linspace(axes[2], axes[3], 100)
x0, x1 = np.meshgrid(x0s, x1s)
X = np.c_[x0.ravel(), x1.ravel()]
y_pred = clf.predict(X).reshape(x0.shape)
# 下面填充一個等高線, alpha表示透明度
plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2)
Poly_kernel_svm_clf = Pipeline((('scaler', StandardScaler()),
('svm_clf', SVC(kernel='poly', degree=3, coef0=1, C=5))
))
Poly_kernel_svm_clf.fit(X, y)
# 下面做一個對比試驗,看看degree的值的變換
Poly_kernel_svm_clf_plus = Pipeline((('scaler', StandardScaler()),
('svm_clf', SVC(kernel='poly', degree=10, coef0=1, C=5))
))
Poly_kernel_svm_clf_plus.fit(X, y)
plt.subplot(121)
plot_predictions(Poly_kernel_svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.title(r'$d=3, r=1, C=5$', fontsize=18)
plt.subplot(122)
plot_predictions(Poly_kernel_svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.title(r'$d=10, r=100, C=5$', fontsize=18)
plt.show()
結果如下:
我們是把數據映射到高維空間,然後再拿回來看效果,實際上並沒有去高維空間做運算。。這就是我們想要展示的多項式核函數,下面學習高斯核函數。
高斯核函數:利用相似度來變換特徵
我們選擇一份一維數據,並在 x1=-2, x1=1 處為其添加兩個高斯函數,接下來讓我門將相似度函數定義為 gamma=0.3 的徑向基核函數(RBF):
例如: x1 = -1:它位於距第一個地標距離為1的地方,距離第二個地標距離為2。因此其新特徵為 x2 = exp(-0.3*1^2)=0.74 ,並且 x3 = exp(-0.3 * 2^2)=0.3。
圖如下:
這裏說一下,就是假設 X2和 X3為兩個高斯函數,我們看 x這個點距離兩個地標的距離。離高斯分佈的中心越近,就越發生什麼。。經過計算出來距離兩個地標的距離,我們就可以依此類推,來計算所有一維坐標相對應的二維坐標。(二維坐標就是距離兩個高斯函數的距離)。
我們這裏用相似度特徵來替換原本的特徵。
下面我們做一個實驗,我們只看 gamma的變換,高斯函數的開口變化:
X1D = np.linspace(-4, 4, 9).reshape(-1, 1)
X2D = np.c_[X1D, X1D ** 2]
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
def gaussian_rbf(x, landmark, gamma):
return np.exp(-gamma * np.linalg.norm(x - landmark, axis=1) ** 2)
gamma = 0.3
# 下面進行訓練,得到一個支持向量機的模型(這裏我們沒有訓練,直接畫出來了)
# 因為測試的數據是我們自己寫的,為了方便,我們自己畫出來,當然你也可以自己做
xls = np.linspace(-4.5, 4.5, 200).reshape(-1, 1)
x2s = gaussian_rbf(xls, -2, gamma)
x3s = gaussian_rbf(xls, 1, gamma)
XK = np.c_[gaussian_rbf(X1D, -2, gamma), gaussian_rbf(X2D, 1, gamma)]
yk = np.array([0, 0, 1, 1, 1, 1, 1, 0, 0])
plt.figure(figsize=(11, 4))
# plt.subplot(121)
plt.grid(True, which='both')
plt.axhline(y=0, color='k')
plt.scatter(x=[-2, 1], y=[0, 0], s=150, alpha=0.5, c='red')
plt.plot(X1D[:, 0][yk == 0], np.zeros(4), 'bs')
plt.plot(X1D[:, 0][yk == 1], np.zeros(5), 'g*')
plt.plot(xls, x2s, 'g--')
plt.plot(xls, x3s, 'b:')
plt.gca().get_yaxis().set_ticks([0, 0.25, 0.5, 0.75, 1])
plt.xlabel(r'$x_1$', fontsize=20)
plt.ylabel(r'Similarity', fontsize=14)
plt.annotate(r'$\mathbf{x}$',
xy=(X1D[3, 0], 0),
xytest=(-0.5, 0.20),
ha='center',
arrowprops=dict(facecolor='black', shrink=0.1),
fontsize=18,
)
plt.text(-2, 0.9, "$x_2$", ha='center', fontsize=20)
plt.text(1, 0.9, "$x_3$", ha='center', fontsize=20)
plt.axis([-4.5, 4.5, -0.1, 1.1])
結果如下(下面我們分別調試gamma,分為0.3 0.8):
理論情況下,我們會得到怎麼維特徵呢?可以對每一個實例(樣本數據點)創建一個地標,此時會將mn 的訓練集轉換成 mm 的訓練集(m表示樣本個數,n表示特徵維度個數)。
SVM中利用核函數的計算技巧,大大降低了計算複雜度:
- 增加gamma 使高斯曲線變窄,因此每個實例的影響範圍都較小,決策邊界最終變得不規則,在個別實例周圍擺動
- 減少gamma 使高斯曲線變寬,因此實例具有更大的影響範圍,並且決策邊界更加平滑
下面做一個對比試驗(gamma值(0.1 0.5), C值(0.001, 1000)):
rbf_kernel_svm_clf = Pipeline((('scaler', StandardScaler()),
('svm_clf', SVC(kernel='rbf', gamma=5, C=0.001))
))
gamma1, gamma2 = 0.1, 5
C1, C2 = 0.001, 1000
hyperparams = (gamma1, C1), (gamma1, C2), (gamma2, C1), (gamma2, C2)
svm_clfs = []
for gamma, C in hyperparams:
rbf_kernel_svm_clf.fit(X, y)
svm_clfs.append(rbf_kernel_svm_clf)
plt.figure(figsize=(11, 7))
for i, svm_clfs in enumerate(svm_clfs):
plt.subplot(221 + i)
plot_predictions(svm_clfs, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
gamma, C = hyperparams[i]
plt.title(r'$\gamma={}, C={}$'.format(gamma, C), fontsize=16)
plt.show()
結果如下:
我們看第一幅圖,邊界比較平穩,沒有過擬合的風險,我們看當 gamma比較大的時候,過擬合的風險卻比較大了。所以說最終我們看的還是高斯函數的開口大還是小,大一點,也就是gamma小,過擬合風險小,反之同理。
完整代碼請參考我的GitHub(地址:https://github.com/LeBron-Jian/MachineLearningNote)。
完整代碼及其數據,請移步小編的GitHub
傳送門:請點擊我
如果點擊有誤:https://github.com/LeBron-Jian/MachineLearningNote
參考文獻:https://blog.csdn.net/BIT_666/article/details/79979580
https://www.cnblogs.com/tonglin0325/p/6107114.html
https://cloud.tencent.com/developer/article/1146077
https://www.cnblogs.com/xiaoyh/p/11604168.html
https://www.cnblogs.com/pinard/p/6126077.html
https://www.cnblogs.com/pinard/p/6117515.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化