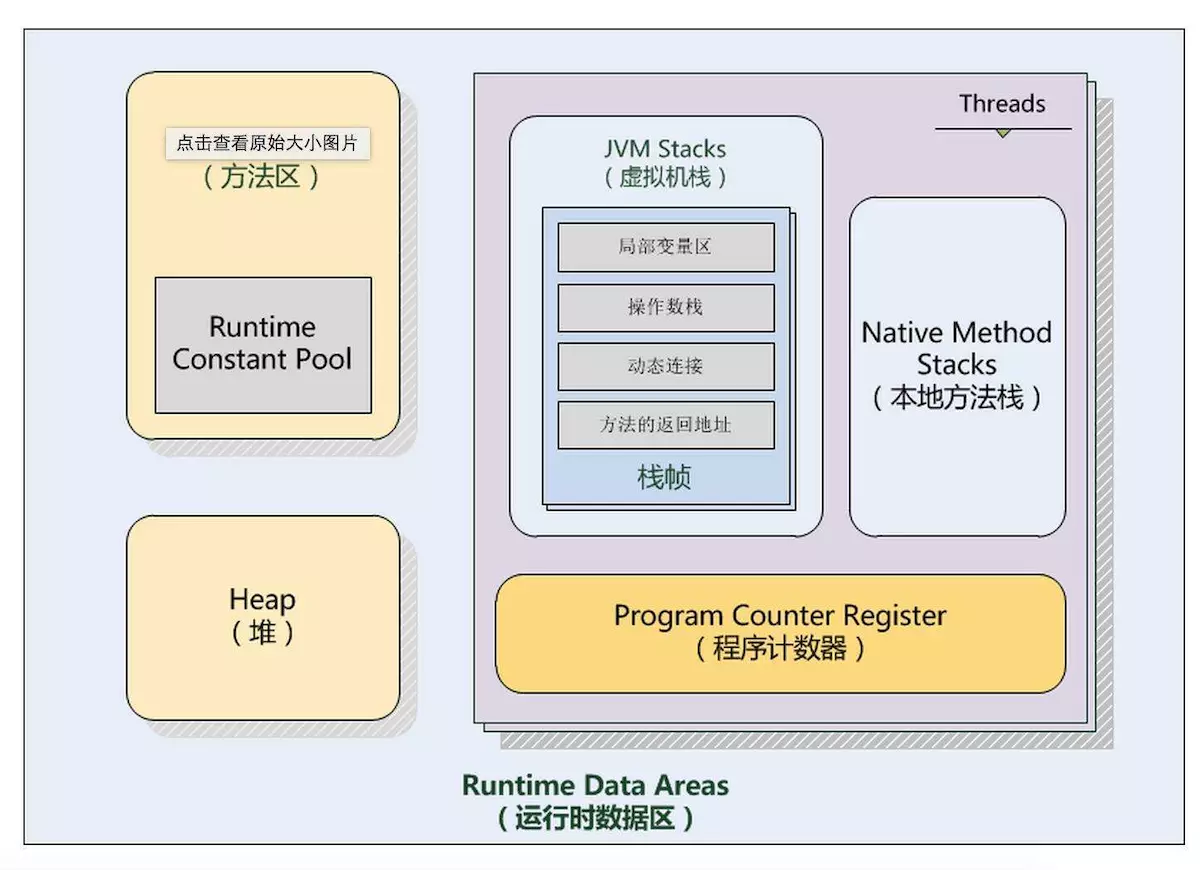
Java內存模型
(圖源: )
| 區域名 | 英文名 | 訪問權限 | 作用 | 備註 |
|---|---|---|---|---|
| 程序計數器 | Program Counter Register | 線程隔離 | 標記待取的下一條執行的指令 | 執行Native方法時為空; JVM規範中唯一不會發生OutOfMemoryError的區域 |
| 虛擬機棧 | VM Stack | 線程隔離 | 每個Java方法執行時創建,用於存儲局部變量表,操作棧,動態鏈接,方法出口等信息 | 方法執行的內存模型 |
| 本地方法棧 | Native Method Stack | 線程隔離 | Native方法執行時使用 | JVM規範沒有強制規定,如Hotspot將VM和Native兩個方法棧合二為一 |
| Java堆 | Java Heap | 線程共享 | 存放對象實例 | 更好的回收內存 vs 更快的分配內存 |
| 方法區 | Method Area | 線程共享 | 存儲已被虛擬機加載的類信息、常量、靜態變量、即時編譯器編譯后的代碼等數據 | JVM規範不強制要求做垃圾收集 |
| 運行時常量池 | Runtime Constant Pool | 線程共享 | 方法區的一部分 | |
| 直接內存 | Direct Memory | – | 堆外內存,通過堆的DirectByteBuffer訪問 | 不是運行時數據區的一部分,但也可能OutOfMemoryError |
對象的創建——new的時候發生了什麼
討論僅限於普通Java對象,不包括數組和Class對象。
- 常量池查找類的常量引用,如果沒有先做類加載
- 分配內存,視堆內存是否是規整(由垃圾回收器是否具有壓縮功能而定)而使用“指針碰撞”或“空閑列表”模式
- 內存空間初始化為零值,可能提前在線程創建時分配TLAB時做初始化
- 設置必要信息,如對象是哪個類的示例、元信息、GC分代年齡等
- 調用
<init>方法
垃圾回收器總結
垃圾回收,針對的都是堆。
分代
- 新生代:適合使用複製算法, 以下三個區一般佔比為8:1:1
- Eden 新對象誕生區
- From Survivor 上一次GC的倖存者(見“GC種類-minor GC”)
- To Survivor 本次待存放倖存者的區域
- 老年代:存活時間較久的,大小較大的對象,因此使用標記-整理或標記-清除算法比較合適
- 永久代:存放類信息和元數據等不太可能回收的信息。Java8中被元空間(Metaspace)代替,不再使用堆,而是物理內存。
分代的原因
- 不同代的對象生命周期不同,可以針對性地使用不同的垃圾回收算法
- 不同代可以分開進行回收
回收算法
| 名稱 | 工作原理 | 優點 | 缺點 |
|---|---|---|---|
| 標記-清除 | 對可回收對對象做一輪標記,標記完成后統一回收被標記的對象 | 易於理解,內存利用率高 | 效率問題;內存碎片;分配大對象但無空間時提前GC |
| 複製 | 內存均分兩塊,只使用其中一塊。回收時將這一塊存活對象全部複製到另一塊 | 效率高 | 可用空間減少; 空間不夠時需老年代分配擔保 |
| 標記-整理 | 對可回收對對象做一輪標記,標記完成后將存活對象統一左移,清理掉邊界外內存 | 內存利用率高 | 效率問題 |
標記-X算法適用於老年代,複製算法適用於新生代。
GC種類
- Minor GC,只回收新生代,將Eden和From Survivor區的存活對象複製到To Survivor
- Major GC,清理老年代。但因為伴隨着新生代的對象生命周期升級到老年代,一般也可認為伴隨着FullGC。
- FullGC,整個堆的回收
- Mixed GC,G1特有,可能會發生多次回收,可以參考
垃圾回收器小結
| 垃圾回收器名稱 | 特性 | 目前工作分代 | 回收算法 | 可否與Serial配合 | 可否與ParNew配合 | 可否與ParallelScavenge配合 | 可否與SerialOld配合 | 可否與ParallelOld配合 | 可否與CMS配合 | 可否與G1配合 |
|---|---|---|---|---|---|---|---|---|---|---|
| Serial | 單線程 | 新生代 | 複製 | – | – | – | Y | N | Y | N/A |
| ParNew | 多線程 | 新生代 | 複製 | – | – | – | N | N | Y | N/A |
| ParallelScavenge | 多線程, 更關注吞吐量可調節 | 新生代 | 複製 | – | – | – | N | N | Y | N/A |
| SerialOld | 單線程 | 老年代 | 標記-整理 | – | – | – | Y | Y | N | N/A |
| ParallelOld | 多線程 | 老年代 | 標記-整理 | N | N | Y | – | – | – | N/A |
| CMS | 多線程,併發收集,低停頓。但無法處理浮動垃圾,標記-清除會產生內存碎片較多 | 老年代 | 標記-清除 | Y | Y | N | Y | – | – | N/A |
| G1 | 并行併發收集,追求可預測但回收時間,整體內存模型有所變化 | 新生代/老年代 | 整體是標記-整理,局部(兩Region)複製 | N | N | N | N | N | N | – |
在本系列的上一篇文章中,減少FullGC的方式是使用G1代替CMS,計劃在下一篇文章中對比CMS和G1的區別。
理解GC日誌
只舉比較簡單的例子,具體各項的格式視情況分析,不同回收器也會有差異。
2019-11-22T10:28:32.177+0800: 60188.392: [GC (Allocation Failure) 2019-11-22T10:28:32.178+0800: 60188.392: [ParNew: 1750382K->2520K(1922432K), 0.0312604 secs] 1945718K->198045K(4019584K), 0.0315892 secs] [Times: user=0.09 sys=0.01, real=0.03 secs]開始時間-(方括號[)-發生區域(ParNew,命名和GC回收器有關)-回收前大小-回收后大小-(方括號])-GC前堆已使用容量-GC后堆已使用容量大小-回收時間-使用時間詳情(用戶態時間-內核時間-牆上時鐘時間)
注意這裏沒有包括“2019-11-22T10:28:32.177+0800: 60188.392: [GC (Allocation Failure)”這部分的分析。
可借鑒的編程模式
對象分配的併發控制
對象創建是很頻繁的,在線程共享的堆中會遇到併發的問題。兩種解決辦法:
- 同步鎖定:CAS+失敗重試,確保原子性
- 堆中預先給每個線程劃分一小塊內存區域——本地線程分配緩衝(TLAB),TLAB使用完並分配新的TLAB時才做同步鎖定。可看作1的優化。
CAS: Conmpare And Swap,用於實現多線程同步的原子指令。 將內存位置的內容與給定值進行比較,只有在相同的情況下,將該內存位置的內容修改為新的給定值。關於CAS可以參考:
對象訪問的定位方式
前提條件:通過棧上本地變量表的reference訪問堆中的對象及它在方法區的對象類型數據(類信息)
主流的兩種方式,這兩種方式各有優點,可以看出方式2是方式1的優化,但並不是全面超越方式1,無法完全取代。
這裏可以看到要權衡垃圾回收和訪問速度兩方面。
方式1: 直接指針訪問實例數據
reference直接存放對象實例地址,只需要一次訪問即可,執行效率較高。
方式2: 使用句柄池
reference中地址穩定,對象被移動時只需要改句柄池的地址。相對的,訪問實例需要兩次指針定位。
參考資料
- 周志明.著《深入理解JAVA虛擬機》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益