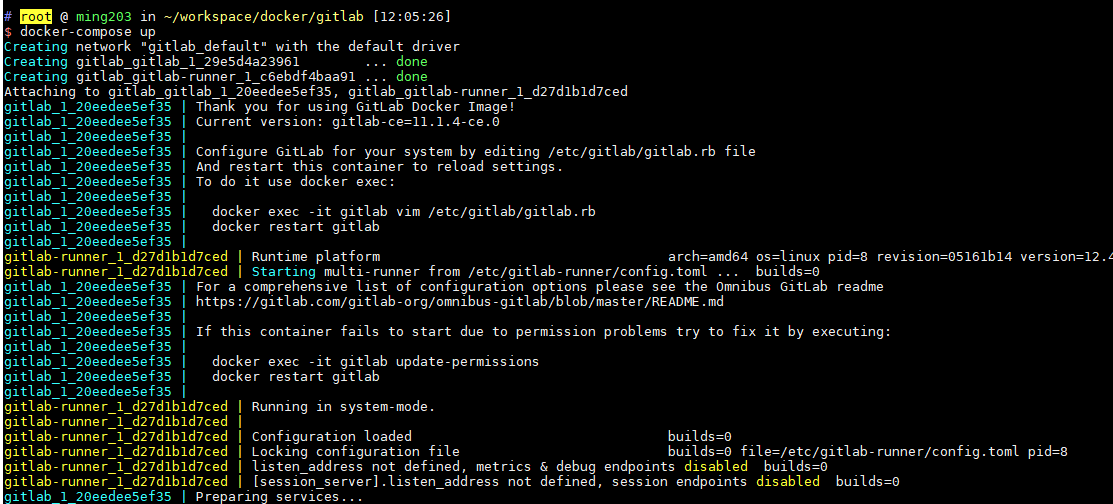
主從架構可以說是互聯網必備的架構了,第一是為了保證服務的高可用,第二是為了實現讀寫分離,你可能熟悉我們常用的 MySQL 數據庫的主從架構,對於我們 redis 來說也不意外,redis 數據庫也有各種各樣的主從架構方式,在主從架構中會涉及到主節點與從節點之間的數據同步,這個數據同步的過程在 redis 中叫做複製,這在篇文章中,我們詳細的聊一聊 redis 的複製技術和主從架構 ,本文主要有以下內容:
主從環境搭建
redis 的實例在默認的情況下都是主節點,所以我們需要修改一些配置來搭建主從架構,redis 的主從架構搭建還是比較簡單的,redis 提供了三種方式來搭建主從架構,在後面我們將就介紹,在介紹之前我們要先了解主從架構的特性:在主從架構中有一個主節點(master)和最少一個從節點(slave),並且數據複製是單向的,只能從主節點複製到從節點,不能由從節點到主節點。
主從架構的建立方式
主從架構的建立有以下三種方式:
- 在 Redis.conf 配置文件中加入 slaveof {masterHost} {masterPort} 命令,隨 Redis 實例的啟動生效
- 在 redis-server 啟動命令后加入 –slaveof {masterHost} {masterPort} 參數
- 在 redis-cli 交互窗口下直接使用命令:slaveof {masterHost} {masterPort}
上面三種方式都可以搭建 Redis 主從架構,我們以第一種方式來演示,其他兩種方式自行嘗試,由於是演示,所以就在本地啟動兩個 Redis 實例,並不在多台機器上啟動 redis 的實例了,我們準備一個端口 6379 的主節點實例,準備一個端口 6480 從節點的實例,端口 6480 的 redis 實例配置文件取名為 6480.conf 並且在裏面添加 slaveof 語句,在配置文件最後加入如下一條語句
slaveof 127.0.0.1 6379
分別啟動兩個 redis 實例,啟動之後他們會自動建立主從關係,關於這背後的原理,我們後面在詳細的聊一聊,先來驗證一下我們的主從架構是否搭建成功,我們先在 6379 master 節點上新增一條數據:
然後再 6480 slave 節點上獲取該數據:
可以看出我們在 slave 節點上已經成功的獲取到了在 master 節點新增的值,說明主從架構已經搭建成功了,我們使用 info replication 命令來查看兩個節點的信息,先來看看主節點的信息
可以看出 6379 端口的實例 role 為 master,有一個正在連接的實例,還有其他運行的信息,我們再來看看 6480 端口的 redis 實例信息
可以看出兩個節點之間相互記錄著對象的信息,這些信息在數據複製時候將會用到。在這裡有一點需要說明一下,默認情況下 slave 節點是只讀的,並不支持寫入,也不建議開啟寫入,我們可以驗證一下,在 6480 實例上寫入一條數據
127.0.0.1:6480> set x 3
(error) READONLY You can't write against a read only replica.
127.0.0.1:6480>
提示只讀,並不支持寫入操作,當然我們也可以修改該配置,在配置文件中 replica-read-only yes 配置項就是用來控制從服務器只讀的,為什麼只能只讀?因為我們知道複製是單向的,數據只能由 master 到 slave 節點,如果在 salve 節點上開啟寫入的話,那麼修改了 slave 節點的數據, master 節點是感知不到的,slave 節點的數據並不能複製到 master 節點上,這樣就會造成數據不一致的情況,所以建議 slave 節點只讀。
主從架構的斷開
主從架構的斷開同樣是 slaveof 命令,在從節點上執行 slaveof no one 命令就可以與主節點斷開追隨關係,我們在 6480 節點上執行 slaveof no one 命令
127.0.0.1:6480> slaveof no one
OK
127.0.0.1:6480> info replication
# Replication
role:master
connected_slaves:0
master_replid:a54f3ba841c67762d6c1e33456c97b94c62f6ac0
master_replid2:e5c1ab2a68064690aebef4bd2bd4f3ddfba9cc27
master_repl_offset:4367
second_repl_offset:4368
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:4367
127.0.0.1:6480>
執行完 slaveof no one 命令之後,6480 節點的角色立馬恢復成了 master ,我們再來看看時候還和 6379 實例連接在一起,我們在 6379 節點上新增一個 key-value
127.0.0.1:6379> set y 3
OK
在 6480 節點上 get y
127.0.0.1:6480> get y
(nil)
127.0.0.1:6480>
在 6480 節點上獲取不到 y ,因為 6480 節點已經跟 6379 節點斷開的聯繫,不存在主從關係了,slaveof 命令不僅能夠斷開連接,還能切換主服務器,使用命令為 slaveof {newMasterIp} {newMasterPort},我們讓 6379 成為 6480 的從節點, 在 6379 節點上執行 slaveof 127.0.0.1 6480 命令,我們在來看看 6379 的 info replication
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6480
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:4367
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:99624d4b402b5091552b9cb3dd9a793a3005e2ea
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:4367
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:4368
repl_backlog_histlen:0
127.0.0.1:6379>
6379 節點的角色已經是 slave 了,並且主節點的是 6480 ,我們可以再看看 6480 節點的 info replication
127.0.0.1:6480> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6379,state=online,offset=4479,lag=1
master_replid:99624d4b402b5091552b9cb3dd9a793a3005e2ea
master_replid2:a54f3ba841c67762d6c1e33456c97b94c62f6ac0
master_repl_offset:4479
second_repl_offset:4368
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:4479
127.0.0.1:6480>
在 6480 節點上有 6379 從節點的信息,可以看出 slaveof 命令已經幫我們完成了主服務器的切換。
複製技術的原理
redis 的主從架構好像很簡單一樣,我們就執行了一條命令就成功搭建了主從架構,並且數據複製也沒有問題,使用起來確實簡單,但是這背後 redis 還是幫我們做了很多的事情,比如主從服務器之間的數據同步、主從服務器的狀態檢測等,這背後 redis 是如何實現的呢?接下來我們就一起看看
數據複製原理
我們執行完 slaveof 命令之後,我們的主從關係就建立好了,在這個過程中, master 服務器與 slave 服務器之間需要經歷多個步驟,如下圖所示:
slaveof 命令背後,主從服務器大致經歷了七步,其中權限驗證這一步不是必須的,為了能夠更好的理解這些步驟,就以我們上面搭建的 redis 實例為例來詳細聊一聊各步驟。
1、保存主節點信息
在 6480 的客戶端向 6480 節點服務器發送 slaveof 127.0.0.1 6379 命令時,我們會立馬得到一個 OK
127.0.0.1:6480> slaveof 127.0.0.1 6379
OK
127.0.0.1:6480>
這時候數據複製工作並沒有開始,數據複製工作是在返回 OK 之後才開始執行的,這時候 6480 從節點做的事情是將給定的主服務器 IP 地址 127.0.0.1 以及端口 6379 保存到服務器狀態的 masterhost 屬性和 masterport 屬性裏面
2、建立 socket 連接
在 slaveof 命令執行完之後,從服務器會根據命令設置的 IP 地址和端口,跟主服務器創建套接字連接, 如果從服務器能夠跟主服務器成功的建立 socket 連接,那麼從服務器將會為這個 socket 關聯一個專門用於處理複製工作的文件事件處理器,這個處理器將負責後續的複製工作,比如接受全量複製的 RDB 文件以及服務器傳來的寫命令。同樣主服務器在接受從服務器的 socket 連接之後,將為該 socket 創建一個客戶端狀態,這時候的從服務器同時具有服務器和客戶端兩個身份,從服務器可以向主服務器發送命令請求而主服務器則會向從服務器返回命令回復。
3、發送 ping 命令
從服務器與主服務器連接成功后,做的第一件事情就是向主服務器發送一個 ping 命令,發送 ping 命令主要有以下目的:
- 檢測主從之間網絡套接字是否可用
- 檢測主節點當前是否可接受處理命令
在發送 ping 命令之後,正常情況下主服務器會返回 pong 命令,接受到主服務器返回的 pong 回復之後就會進行下一步工作,如果沒有收到主節點的 pong 回復或者超時,比如網絡超時或者主節點正在阻塞無法響應命令,從服務器會斷開複製連接,等待下一次定時任務的調度。
4、身份驗證
從服務器在接收到主服務器返回的 pong 回復之後,下一步要做的事情就是根據配置信息決定是否需要身份驗證:
- 如果從服務器設置了 masterauth 參數,則進行身份驗證
- 如果從服務器沒有設置 masterauth 參數,則不進行身份驗證
在需要身份驗證的情況下,從服務器將就向主服務器發送一條 auth 命令,命令參數為從服務器 masterauth 選項的值,舉個例子,如果從服務器的配置里將 masterauth 參數設置為:123456,那麼從服務器將向主服務器發送 auth 123456 命令,身份驗證的過程也不是一帆風順的,可能會遇到以下幾種情況:
- 從服務器通過 auth 命令發送的密碼與主服務器的 requirepass 參數值一致,那麼將繼續進行後續操作,如果密碼不一致,主服務將返回一個 invalid password 錯誤
- 如果主服務器沒有設置 requirepass 參數,那麼主服務器將返回一個 no password is set 錯誤
所有的錯誤情況都會令從服務器中止當前的複製工作,並且要從建立 socket 開始重新發起複制流程,直到身份驗證通過或者從服務器放棄執行複製為止
5、發送端口信息
在身份驗證通過後,從服務器將執行 REPLCONF listening 命令,向主服務器發送從服務器的監聽端口號,例如在我們的例子中從服務器監聽的端口為 6480,那麼從服務器將向主服務器發送 REPLCONF listening 6480 命令,主服務器接收到這個命令之後,會將端口號記錄在從服務器所對應的客戶端狀態的 slave_listening_port 屬性了,也就是我們在 master 服務器的 info replication 裏面看到的 port 值。
6、數據複製
數據複製是最複雜的一塊了,由 psync 命令來完成,從服務器會向主服務器發送一個 psync 命令來進行數據同步,在 redis 2.8 版本以前使用的是 sync 命令,除了命令不同之外,在複製的方式上也有很大的不同,在 redis 2.8 版本以前使用的都是全量複製,這對主節點和網絡會造成很大的開銷,在 redis 2.8 版本以後,數據同步將分為全量同步和部分同步。
-
全量複製:一般用於初次複製場景,不管是新舊版本的 redis 在從服務器第一次與主服務連接時都將進行一次全量複製,它會把主節點的全部數據一次性發給從節點,當數據較大時,會對主節點和網絡造成很大的開銷,redis 的早期版本只支持全量複製,這不是一種高效的數據複製方式
-
部分複製:用於處理在主從複製中因網絡閃斷等原因造成的數據丟失 場景,當從節點再次連上主節點后,如果條件允許,主節點會補發丟失數據 給從節點。因為補發的數據遠遠小於全量數據,可以有效避免全量複製的過高開銷,部分複製是對老版複製的重大優化,有效避免了不必要的全量複製操作
redis 之所以能夠支持全量複製和部分複製,主要是對 sync 命令的優化,在 redis 2.8 版本以後使用的是一個全新的 psync 命令,命令格式為:psync {runId} {offset},這兩個參數的意義:
- runId:主節點運行的id
- offset:當前從節點複製的數據偏移量
也許你對上面的 runid、offset 比較陌生,沒關係,我們先來看看下面三個概念:
1、複製偏移量
參与複製的主從節點都會分別維護自身複製偏移量:主服務器每次向從服務器傳播 N 個字節的數據時,就將自己的偏移量的值加上 N,從服務器每次接收到主服務器傳播的 N個字節的數據時,將自己的偏移量值加上 N。通過對比主從服務器的複製偏移量,就可以知道主從服務器的數據是否一致,如果主從服務器的偏移量總是相同,那麼主從數據一致,相反,如果主從服務器兩個的偏移量並不相同,那麼說明主從服務器並未處於數據一致的狀態,比如在有多個從服務器時,在傳輸的過程中某一個服務器離線了,如下圖所示:
由於從服務器A 在數據傳輸時,由於網絡原因掉線了,導致偏移量與主服務器不一致,那麼當從服務器A 重啟並且與主服務器連接成功后,重新向主服務器發送 psync 命令,這時候數據複製應該執行全量複製還是部分複製呢?如果執行部分複製,主服務器又如何補償從服務器A 在斷線期間丟失的那部分數據呢?這些問題的答案都在複製積壓緩衝區裏面
2、複製積壓緩衝區
複製積壓緩衝區是保存在主節點上的一個固定長度的隊列,默認大小為 1MB,當主節點有連接的從節點(slave)時被創建,這時主節點(master) 響應寫命令時,不但會把命令發送給從節點,還會寫入複製積壓緩衝區,如下圖所示:
因此,主服務器的複製積壓緩衝區裏面會保存着一部分最近傳播的寫命令,並且複製積壓緩衝區會為隊列中的每個字節記錄相應的複製偏移量。所以當從服務器重新連上主服務器時,從服務器通過 psync 命令將自己的複製偏移量 offset 發送給主服務器,主服務器會根據這個複製偏移量來決定對從服務器執行何種數據同步操作:
- 如果從服務器的複製偏移量之後的數據仍然存在於複製積壓緩衝區裏面,那麼主服務器將對從服務器執行部分複製操作
- 如果從服務器的複製偏移量之後的數據不存在於複製積壓緩衝區裏面,那麼主服務器將對從服務器執行全量複製操作
3、服務器運行ID
每個 Redis 節點啟動后都會動態分配一個 40 位的十六進制字符串作為運行 ID,運行 ID 的主要作用是用來唯一識別 Redis 節點,我們可以使用 info server 命令來查看
127.0.0.1:6379> info server
# Server
redis_version:5.0.5
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:2ef1d58592147923
redis_mode:standalone
os:Linux 3.10.0-957.27.2.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:4.8.5
process_id:25214
run_id:7b987673dfb4dfc10dd8d65b9a198e239d20d2b1
tcp_port:6379
uptime_in_seconds:14382
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:14554933
executable:/usr/local/redis-5.0.5/src/./redis-server
config_file:/usr/local/redis-5.0.5/redis.conf
127.0.0.1:6379>
這裏面有一個run_id 字段就是服務器運行的ID
了解這幾個概念之後,我們一起來看看 psync 命令的運行流程,psync 命令運行流程如下圖所示:
psync 命令的邏輯比較簡單,整個流程分為兩步:
1、從節點發送 psync 命令給主節點,參數 runId 是當前從節點保存的主節點運行ID,參數offset是當前從節點保存的複製偏移量,如果是第一次參与複製則默認值為 -1。
2、主節點接收到 psync 命令之後,會向從服務器返回以下三種回復中的一種:
- 回復 +FULLRESYNC {runId} {offset}:表示主服務器將與從服務器執行一次全量複製操作,其中 runid 是這個主服務器的運行 id,從服務器會保存這個id,在下一次發送 psync 命令時使用,而 offset 則是主服務器當前的複製偏移量,從服務器會將這個值作為自己的初始化偏移量
- 回復 +CONTINUE:那麼表示主服務器與從服務器將執行部分複製操作,從服務器只要等着主服務器將自己缺少的那部分數據發送過來就可以了
- 回復 +ERR:那麼表示主服務器的版本低於 redis 2.8,它識別不了 psync 命令,從服務器將向主服務器發送 sync 命令,並與主服務器執行全量複製
7、命令持續複製
當主節點把當前的數據同步給從節點后,便完成了複製的建立流程。但是主從服務器並不會斷開連接,因為接下來主節點會持續地把寫命令發送給從節點,保證主從數據一致性。
經過上面 7 步就完成了主從服務器之間的數據同步,由於這篇文章的篇幅比較長,關於全量複製和部分複製的細節就不介紹了,全量複製就是將主節點的當前的數據生產 RDB 文件,發送給從服務器,從服務器再從本地磁盤加載,這樣當文件過大時就需要特別大的網絡開銷,不然由於數據傳輸比較慢會導致主從數據延時較大,部分複製就是主服務器將複製積壓緩衝區的寫命令直接發送給從服務器。
心跳檢測
心跳檢測是發生在主從節點在建立複製后,它們之間維護着長連接並彼此發送心跳命令,便以後續持續發送寫命令,主從心跳檢測如下圖所示:
主從節點彼此都有心跳檢測機制,各自模擬成對方的客戶端進行通信,主從心跳檢測的規則如下:
- 主節點默認每隔 10 秒對從節點發送 ping 命令,判斷從節點的存活性和連接狀態。可通過修改 redis.conf 配置文件裏面的 repl-ping-replica-period 參數來控制發送頻率
- 從節點在主線程中每隔 1 秒發送 replconf ack {offset} 命令,給主節點 上報自身當前的複製偏移量,這條命令除了檢測主從節點網絡之外,還通過發送複製偏移量來保證主從的數據一致
主節點根據 replconf 命令判斷從節點超時時間,體現在 info replication 統 計中的 lag 信息中,我們在主服務器上執行 info replication 命令:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6480,state=online,offset=25774,lag=0
master_replid:c62b6621e3acac55d122556a94f92d8679d93ea0
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:25774
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:25774
127.0.0.1:6379>
可以看出 slave0 字段的值最後面有一個 lag,lag 表示與從節點最後一次通信延遲的秒數,正常延遲應該在 0 和 1 之間。如果超過 repl-timeout 配置的值(默認60秒),則判定從節點下線並斷開複製客戶端連接,如果從節點重新恢復,心跳檢測會繼續進行。
主從拓撲架構
Redis的主從拓撲結構可以支持單層或多層複製關係,根據拓撲複雜性可以分為以下三種:一主一從、一主多從、樹狀主從架構
一主一從結構
一主一從結構是最簡單的複製拓撲結構,我們前面搭建的就是一主一從的架構,架構如圖所示:
一主一從架構用於主節點出現宕機時從節點 提供故障轉移支持,當應用寫命令併發量較高且需要持久化時,可以只在從節點上開啟 AOF,這樣既保證數據安全性同時也避免了持久化對主節點的性能干擾。但是這裡有一個坑,需要你注意,就是當主節點關閉持久化功能時, 如果主節點脫機要避免自動重啟操作。因為主節點之前沒有開啟持久化功能自動重啟后數據集為空,這時從節點如果繼續複製主節點會導致從節點數據也被清空的情況,喪失了持久化的意義。安全的做法是在從節點上執行 slaveof no one 斷開與主節點的複製關係,再重啟主節點從而避免這一問題
一主多從架構
一主多從架構又稱為星形拓撲結構,一主多從架構如下圖所示:
一主多從架構可以實現讀寫分離來減輕主服務器的壓力,對於讀佔比較大的場景,可以把讀命令發送到 從節點來分擔主節點壓力。同時在日常開發中如果需要執行一些比較耗時的讀命令,如:keys、sort等,可以在其中一台從節點上執行,防止慢查詢對主節點造成阻塞從而影響線上服務的穩定性。對於寫併發量較高的場景,多個從節點會導致主節點寫命令的多次發送從而過度消耗網絡帶寬,同時也加重了主節點的負載影響服務穩定性。
樹狀主從架構
樹狀主從架構又稱為樹狀拓撲架構,樹狀主從架構如下圖所示:
樹狀主從架構使得從節點不但可以複製主節 數據,同時可以作為其他從節點的主節點繼續向下層複製。解決了一主多從架構中的不足,通過引入複製中 間層,可以有效降低主節點負載和需要傳送給從節點的數據量。如架構圖中,數據寫入節點A 後會同步到 B 和 C節點,B節點再把數據同步到 D 和 E節點,數據實現了一層一層的向下複製。當主節點需要掛載多個從節點時為了避免對主節點的性能干擾,可以採用樹狀主從結構降低主節點壓力。
最後
目前互聯網上很多大佬都有 Redis 系列教程,如有雷同,請多多包涵了。原創不易,碼字不易,還希望大家多多支持。若文中有所錯誤之處,還望提出,謝謝。
歡迎掃碼關注微信公眾號:「平頭哥的技術博文」,和平頭哥一起學習,一起進步。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※收購3c,收購IPHONE,收購蘋果電腦-詳細收購流程一覽表
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品在網路上成為最夯、最多人討論的話題?
※高價收購3C產品,價格不怕你比較
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!